原标题:460亿个晶体管!寒武纪首颗7nm AI芯片亮相,全面支持训练和推理

芯东西(公众号:aichip001)
编辑 | 心缘
芯东西1月21日消息,今天,寒武纪正式亮出其首颗AI训练芯片思元290及玄思1000智能加速器。
该芯片采用台积电7nm制程工艺,集成460亿个晶体管,支持MLUv02扩展架构,全面支持AI训练、推理或混合型人工智能计算加速任务。
目前寒武纪思元290芯片及加速卡已与部分硬件合作伙伴完成适配,并已实现规模化出货。

▲寒武纪智能加速卡MLU290-M5
一、芯片采用 MLUv02 扩展架构,峰值算力较上一代提升 4 倍
寒武纪训练产品线采用自适应精度训练方案,面向互联网、金融、交通、能源、电力和制造等领域的复杂AI应用场景。MLUv02架构为寒武纪MLU200全产品线共享,满足云、边、端三个场景的算力需求。
云端训练对AI算力的要求更为苛刻,因此寒武纪对思元290的MLUv02架构进行了多项扩展,包括业内领先的MLU-Link多芯互联技术、高带宽HBM2内存、高速片上总线NOC以及新一代PCIe 4.0接口。
相比寒武纪思元270芯片,思元290芯片实现峰值算力提升4倍、内存带宽提高12倍、芯片间通讯带宽提高19倍,结合7nm制程可提供更优性能功耗比,以及多MLU系统的扩展能力。
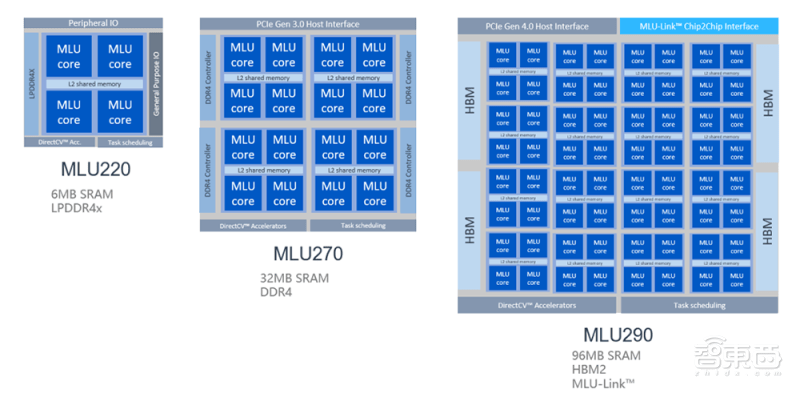
▲MLU290的MLUv02架构进行了多项扩展
寒武纪首款训练智能加速卡MLU290-M5,搭载思元290智能芯片,采用开放加速模块OAM设计,具备64个MLU核、1.23TB/s内存带宽及全新MLU-Link多芯互联技术,最大散热功耗350W,AI峰值算力达1024 TOPS(INT4)。
寒武纪MLU290-M5智能加速卡搭载了思元290智能芯片,采用开放加速模块OAM设计,具备64个MLU Core,1.23TB/s内存带宽以及全新MLU-Link多芯互联技术,在350W的最大散热功耗下提供AI算力高达1024 TOPS(INT4)。

▲寒武纪智能加速卡MLU290-M5产品规格
二、一台玄思 1000 计算单元可替代一个小型超算中心
寒武纪玄思1000智能加速器可在2U机箱内集成4颗思元290智能芯片,首款智能加速器玄思1000包含4片思元290智能加速卡,最大AI算力超过4100万亿次每秒(4.1 PetaOPS INT4)。
寒武纪称,一台玄思1000计算单元就足以替代一个小型传统超级计算中心。
玄思1000采用了高速本地闪存、Mellanox InfiniBand网络,对外提供高速MLU-Link接口,打破智能芯片、服务器、POD与集群的传统数据中心横向扩展架构,实现AI算力在计算中心级纵向扩展。

▲玄思1000支持计算中心级纵向扩展
玄思1000内置高带宽低延时的MLU-Link多芯互联技术,实现内部4颗思元290进行高速互联,同时打破服务器、紧耦合微集群(POD)与集群的传统数据中心横向扩展架构,将AIDC构建为节点、POD乃至超大规模混合扩展架构(Hybrid Scale-out),实现AI算力计算中心级纵向扩展,满足高性能、高扩展性、灵活性、高鲁棒性的要求。
三、并行通讯总带宽提升 19 倍,重新思考未来 AIDC 基础架构
算力已成为驱动AI产业化和产业AI化发展的关键要素。近年来,AI算法模型的复杂程度高速增长,对算力和训练速度提出了更高的要求。为了构建更强大的计算平台,多芯片间的互联技术已成为市场刚需。
下一代人工智能计算中心(AIDC)要求更多智能芯片无缝协同、并行运行的同时,还能保持高计算效率,从而提供超级巨大的算力,以应对超大规模训练的需要。
对此,寒武纪重新思考了未来AIDC的基础架构,在玄思1000智能加速器内部和外部采用统一的MLU-Link多芯互联技术进行通讯,使得思元290智能芯片的互联范围可以从单机扩展到POD乃至整个计算中心。

▲思元290采用MLU-Link多芯互联技术进行互联,带宽、灵活性全面优于PCIe 3.0
寒武纪推出的MLU-Link多芯互联技术,首次搭载于寒武纪思元290芯片,每颗思元290的多芯互联总带宽高达600GB/s。该技术支持多颗思元芯片无缝互联,支持跨系统互联,将纵向扩展能力整合到整个AIDC,可端到端加速大型AI模型训练。
MLU-Link具备丰富的互联特性,突破PCIe带宽和互联的瓶颈,相比思元270芯片通过PCIe并行的通讯方式,带宽提高19倍。

▲思元290相较思元270并行通讯总带宽提升19倍
玄思1000配置8个对外互联的MLU-Link接口,支持跨系统互联构建MLU POD。标准配置支持MLU POD 16、24、32。

▲玄思1000支持8个400G MLU-Link和2个200G网络接口,总带宽高达3600 Gbps,是传统异构服务器的2倍
在POD内部,所有思元290芯片均可通过MLU-Link多芯互联技术进行通讯,在带宽和延时方面实现了突破。
在POD外部,通过玄思1000内置的网卡与其他系统进行通讯,实现了AI训练集群性能、扩展性和鲁棒性的协同提升。
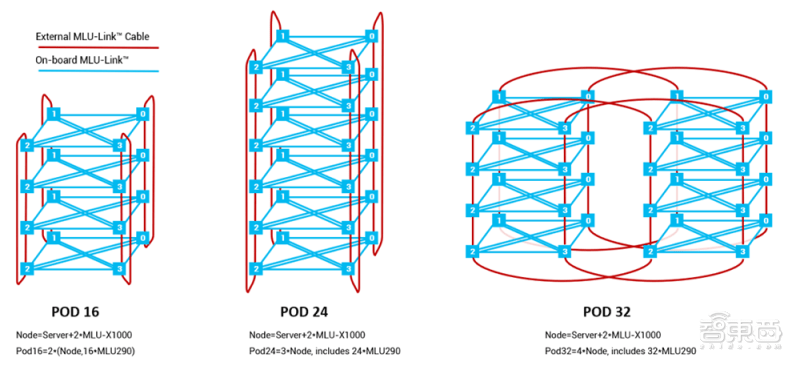
▲POD内所有思元芯片通过MLU-Link全互联
除了标准配置的POD之外,在计算中心条件允许的前提下,通过MLU-Link多芯互联技术,可实现1024颗或更多思元290互联,不需要额外的网卡即可实现无缝加速。
四、支持实现 4 个相互隔离的实例
不同场景下的AI训练对计算和存储的要求千差万别,如何提供更灵活也更稳定的服务,但同时让算力得到充分地利用,是AIDC面临的持续挑战。
寒武纪虚拟化技术vMLU,支持在思元290上实现4个相互隔离的AI计算实例,每个实例独占计算、内存和编解码资源。
实例之间的硬件资源互不干扰,即使在虚拟化环境下,仍可保持90%以上的高效率,帮助客户充分利用硬件资源。

▲思元290上实现4个相互隔离的AI计算实例
vMLU还能帮助思元290芯片提供更好的灵活性。通过热迁移技术,云管理员可将正在运行的AI负载及其应用程序移动到另外一台主机上,从而平衡整个AIDC的负载,并实现更好的容灾功能。

▲vMLU 热迁移
五、搭配寒武纪 Neuware 训练软件栈,支持多种应用训练推理
寒武纪Neuware软件栈为思元290芯片提供完善的软件及应用生态,支持业界主流的TensorFlow和PyTorch等深度学习框架,用户不需要改变使用习惯,即可在思元290芯片上实现图形图像、语音、NLP、搜索推荐等多种应用的训练和推理。
其中,基于Horovod分布式训练框架与MLU-Link多芯互联技术相互配合,使思元290在单机多卡、多机多卡的场景下达到业界领先的训练加速比。
寒武纪Neuware提供完善的开发工具包和社区支持,帮助用户在思元290芯片进行方便、灵活的定制开发及部署工作。配合BANG智能编程语言及配套调试工具,用户可以为自定义的算法提供最佳性能调优。

▲寒武纪Neuware软件栈
结语:寒武纪已建立云边端一体生态
随着寒武纪首颗训练芯片思元290智能芯片及加速卡、玄思1000智能加速器训练产品线亮相,寒武纪已建立“云边端一体、软硬件协同、训练推理融合”的新生态。
在完整产品体系搭建后,下一步,寒武纪不仅将面临研发方面的持续创新优化,也将迎来多样化的人工智能应用场景与需求的产品化考验。