原标题:从近年顶会论文看对比学习最新研究进展
视觉对比学习的核心:对比两图像是不是同一图像的不同变换。
CVPR 2018

论文标题:
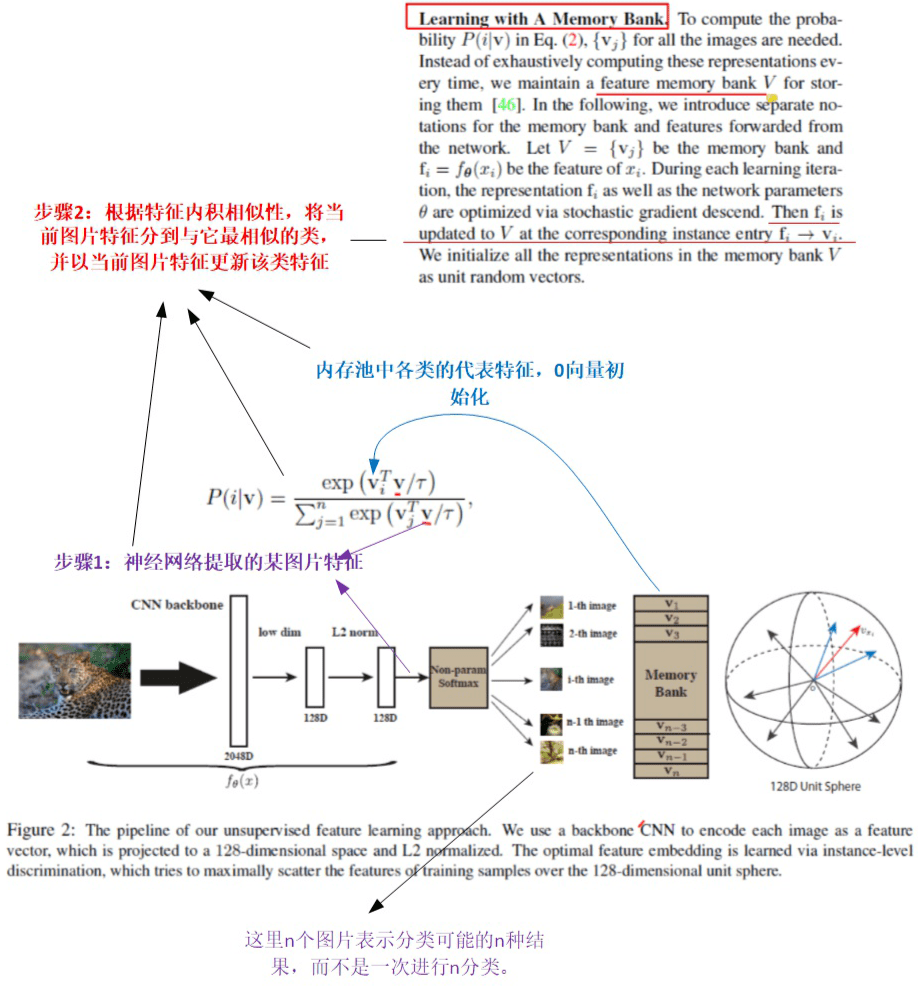
Unsupervised Feature Learning via Non-Parametric Instance Discrimination
论文链接:
https://arxiv.org/abs/1805.01978
代码链接:
https://github.com/zhirongw/lemniscate.pytorch
此篇文章的核心思想可用下图两个简短步骤说明。
CPC

论文标题:
Representation Learning with Contrastive Predictive Coding
论文链接:
https://arxiv.org/abs/1807.03748
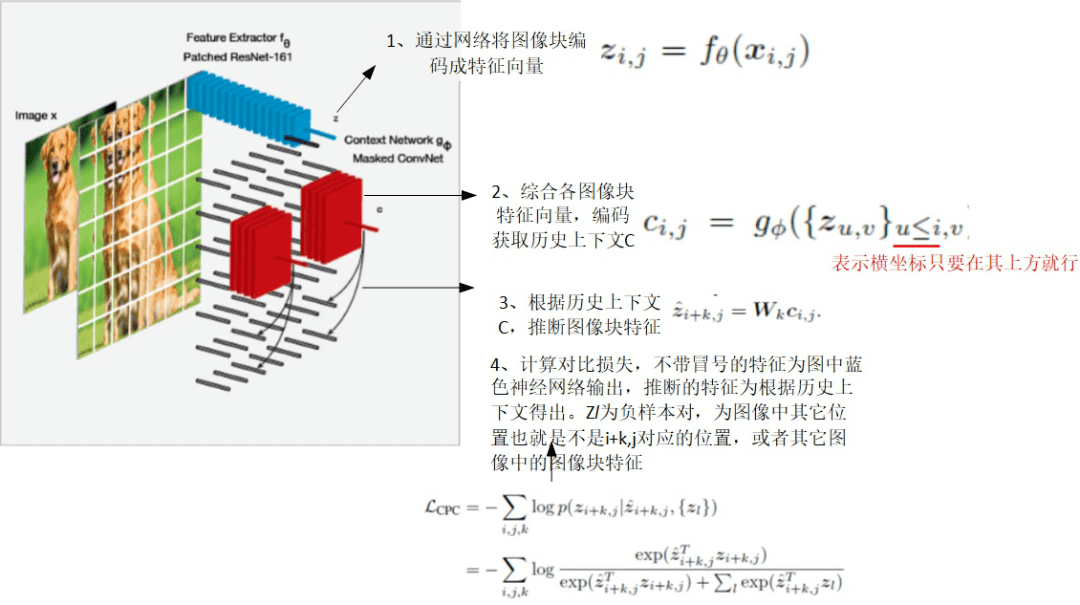
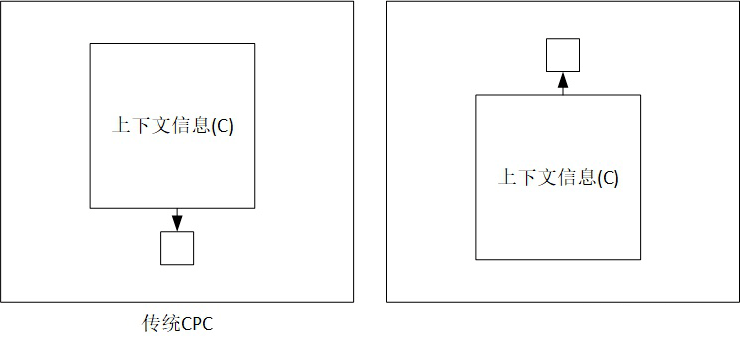
后面提到的第 5 篇文章(CPC V2)对这个文章的总结很好: CPC 通过训练网络根据过去信息预测未来观测来学习特征表示。当用于图像处理时,CPC 通过根据当前图像块上方的图像块们来预测它的表示。

那么怎么预测未来观测了,作者认为,未来预测应根据前面历史上下文来预测,而为了保证未来预测的准确性,就最大化历史上下文与未来预测的关联关系,那么怎么最大化了?就是将未来分为:1)和历史上下文无关的未来;2)和历史上下文有关的未来。
2.1 基本概念
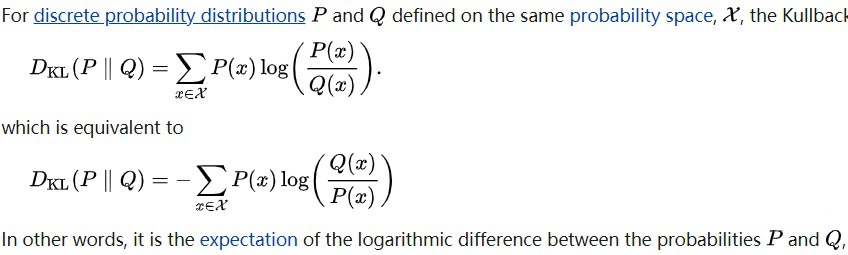
▲ KL计算公式与定义
Mutual Information:两个随机变量的联合分布 P(x,c) 与他们两个边际分布 P(x)P(c) 相乘形成的分布的 KL 距离是为两个随机变量的互信息。也就是两个分布的相似性。如果 KL 越小,说明联合分布就等于边际分布相乘,说明两个变量之间彼此独立,不能相互提供信息。

▲ 文中公式1的计算由来
所以文中提到需要 强化历史上下文 c,与未来状态分布之间的互信息,也就是强化两者之间的相关性,保证我根据上下文 C 预测得到的 x 是准确的。

那么历史上下文怎么来了?
还是从下面第 5 篇文章讲解出发,见下图。
CVPR 2020

论文标题:
Momentum Contrast for Unsupervised Visual Representation Learning
论文链接:
https://arxiv.org/abs/1911.05722
代码链接:
https://github.com/facebookresearch/moco
3.1 对比学习概念泛化与直觉理解
延续 CPC 文章,何老师将对比学习的概念进一步泛化了一番。如下。
对比学习可以认为是 为 检索项(即输入图像)与动态字典(如上篇的特征池)中的各项进行对比,找到最相似的那个(也就是匹配项)。

既然后面作者用了 key,也可以将对比学习训练过程认为:从一堆 key 中找到能开这个门锁的 key,而且这个能开门锁的 key 是从这个门锁倒模而来。
训练时,检索项与其匹配 key 称作正样本对,与其它 key 称为负样本对。损失函数因此定义为如下,其中 k+ 为匹配 key。 如果检索项与匹配 key 特征相似度越高(内积越高,如完全不相关正交内积为 0),损失越小。
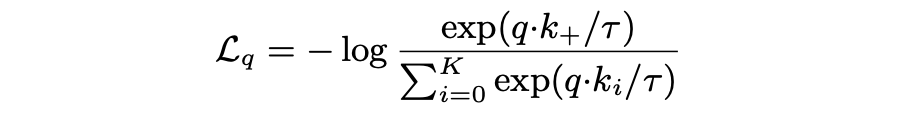
注意,上面检索项与 key 特征输出一般用的同一网络(文中的另一创新就是,key 项编码网络根据检索项编码网络参数进行动量更新,与滑动平均类似),因此该损失函数的本质就在于鼓励网络对于相似图片输出相似特征。

3.2 文中对比学习的实现与训练
其实,对比学习的一个重点就是每次训练迭代的时候正样本对、负样本对怎么来。
一般的:
正样本对都是从当前训练图像经过变换而来。
负样本对:因为训练包中一般有很多图片 N,所以经变换后会有 2N 张图片,所以对于每一张图片,有 2(N-1)张图片与其无关联,因此可以作为其负样本。(例如下面提到的 SimCLR)
这篇文章将 每个批次的历史正样本存入队列并当作后续训练批次的所有图片的负样本。

ICML 2020

论文标题:
A Simple Framework for Contrastive Learning of Visual Representations
论文链接:
https://arxiv.org/abs/2002.05709
代码链接:
https://github.com/google-research/simclr
这篇文章的主要创新就是在检索项和匹配 key 项后面,进一步加了个线性变换。
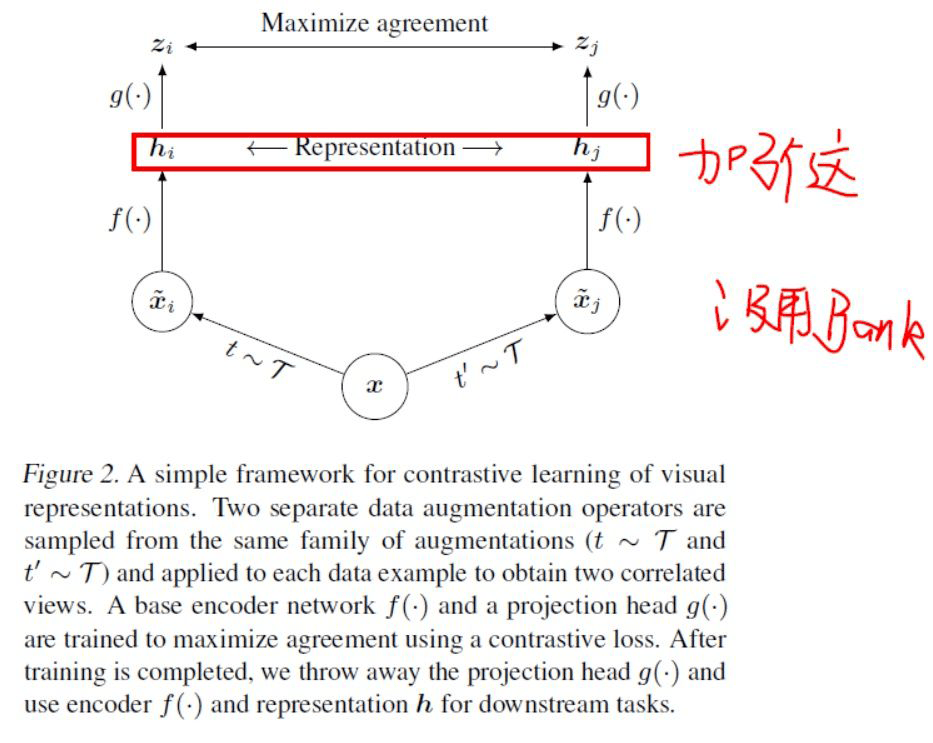
然后没有用Bank,但用了超大的 training batch,普通玩家玩不起。
论文还研究了 t 撇到大 T 这个图像增广方式对于性能的影响。影响结果如表所示。
除了最后一列以及对角线以外,其它非对角线的性能都是连续用两次增广的效果。由结果可以看出, 仅用单种增广的效果一般都要差于连续两次变换的效果。
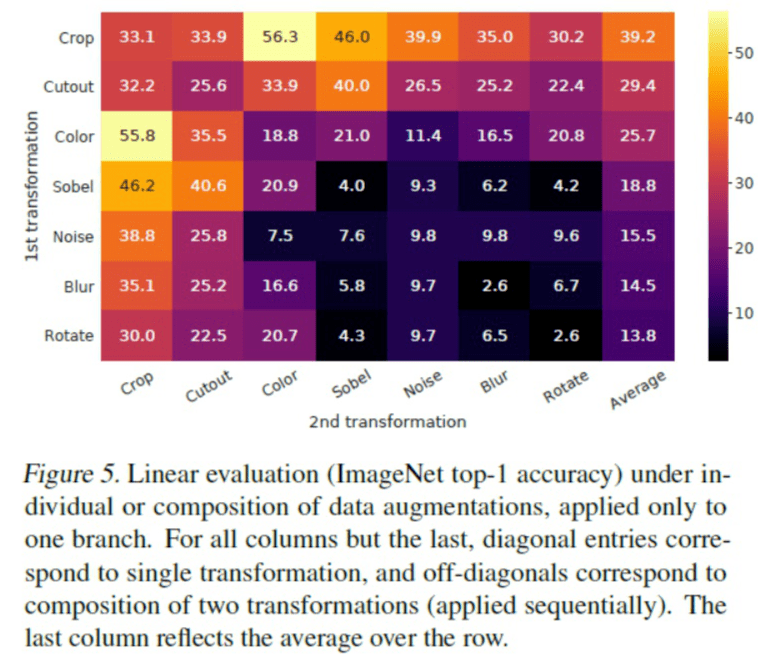
且随机裁剪加随机颜色调整效果最突出。

并由此得出一个重要结论:对比学习对数据增广的强度要求更高。

ICML 2020

论文标题:
Data-Efficient Image Recognition with Contrastive Predictive Coding
论文链接:
https://arxiv.org/abs/1905.09272
从下面这篇图可以看出,这篇文章好像只是把 CPC 拿来作为特征提取器, 然后将这种提取的特征作为初始输入,送入至普通的卷积网络(如 ResNet33,这个地方就是与常规的区别,常规搞法一般后面只接一个浅层网络)。然后看看引入 CPC 后,视觉任务是不是对标签的要求会降低。
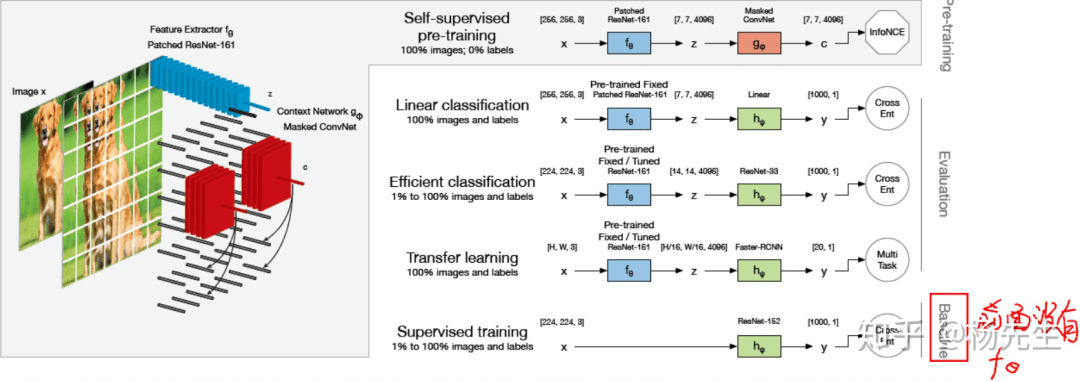
所以作者将一个经典网络 ResNet 作为 Baseline,然后加入 CPC 特征编码模块看对 Baseline 性能的影响。
如果只是这样,好像创新度说不过去,所以作者通过实验分析,发现了将 CPC 用作特征编码的更佳方式,所以对基础 CPC 做了几处改进,并将原 CPC 性能提升了 20 多个点。各改进对 CPC 的性能提升都在下图了。
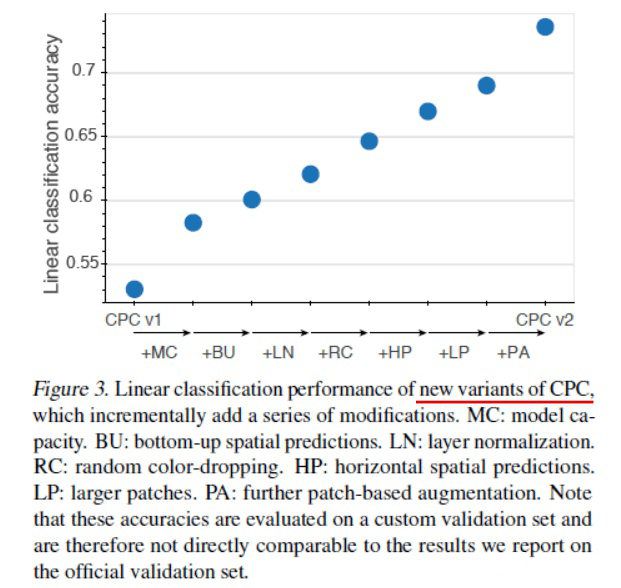
MC:增加模型容量。出发点:自监督学习适合大网络。
LN:将块归一化替换为层归一化。出发点:发现块归一化不利于对比学习。
BU+HP:除了仅利用上图中的上部图像块作为历史上下文预测,还 增加了左右(对应 HP)、上(BU:如下图)的预测。注意:图中大方块与小方块实际上是有一部分重叠的,这里省略了。
LP:更大的采样图像块。
PA:图像块数据增广。
其它的 可以在文中一一对应。
ICLR 2019

论文标题:
Learning Deep Representations by Mutual Information Estimation and Maximization
论文链接:
https://arxiv.org/abs/1808.06670
代码链接:
https://github.com/rdevon/DIM

这篇文章介绍里和 CPC 对比了一番,从中可以看出这篇文章的一些思想。
文章认为因为 CPC 预测前需要统计好一些列历史特征,且每次预测历史特征都不一样。所以称它为有序的自回归。而这篇文章,所有点的特征预测都根据同一全局特征来预测。

另外文章的具体做法,从下面三张图也还比较好理解。
第一幅图就是说明了平时 CNN 编码提取 图像块特征的流程。
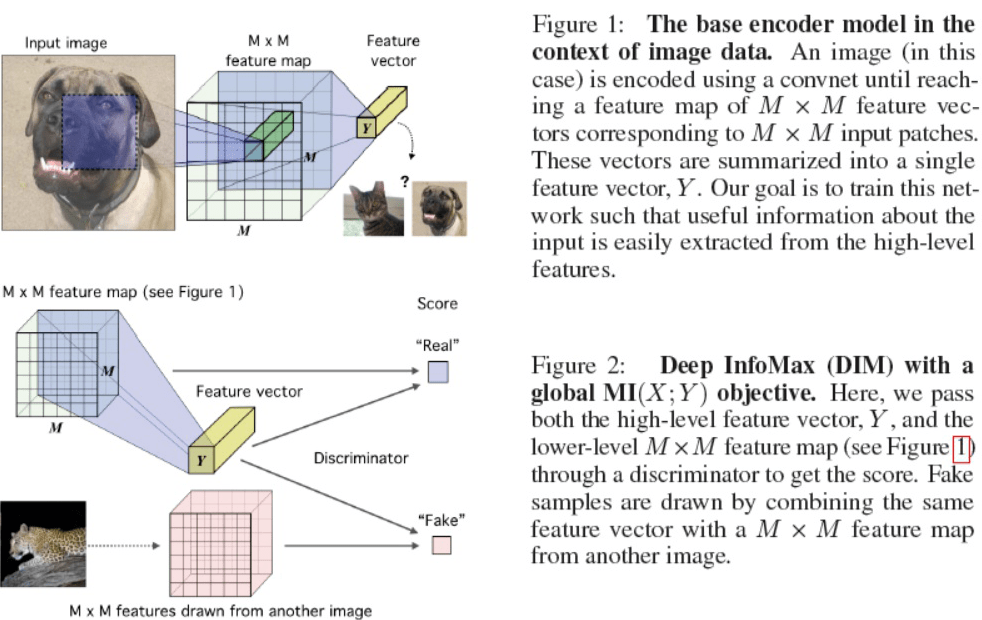
第二幅图:最大化 feature map 和 全局特征 Y 之间的互信息?(具体实现文中附件有图示说明)负样本来自另外的图片。
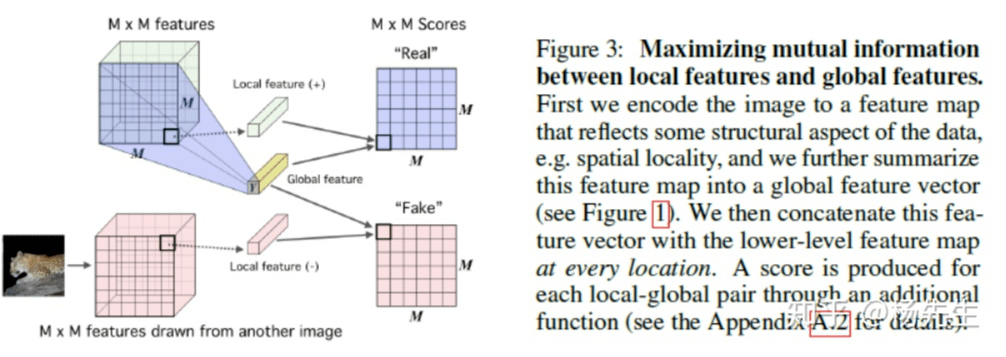
第三幅图:最大化局部特征和全局特征之间的互信息。
ECCV 2020

论文标题:
Contrastive Multiview Coding
论文链接:
https://arxiv.org/abs/1906.05849
代码链接:
https://github.com/HobbitLong/CMC
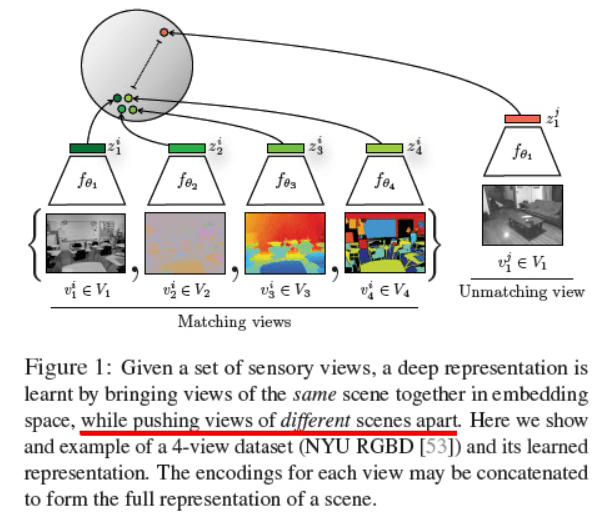
这篇文章对之前的对比学习也梳理的比较好,它认为所有对比学习都可以认为是 让网络对同一 “信号”(信号可以是图像也可是文本)的不同视角输出的特征之间关联关系很大(例如相似)。例如 CPC 可以认为是 当前与未来两种视角的对比,而 DeepInfomax 可认为网络的 输入和输出是信号的两种不同视角。
所以作者将以前一般仅考虑 两种视角之间的对比,扩展到多种视角对比,而且在扩展的时候考虑以下两种情况。
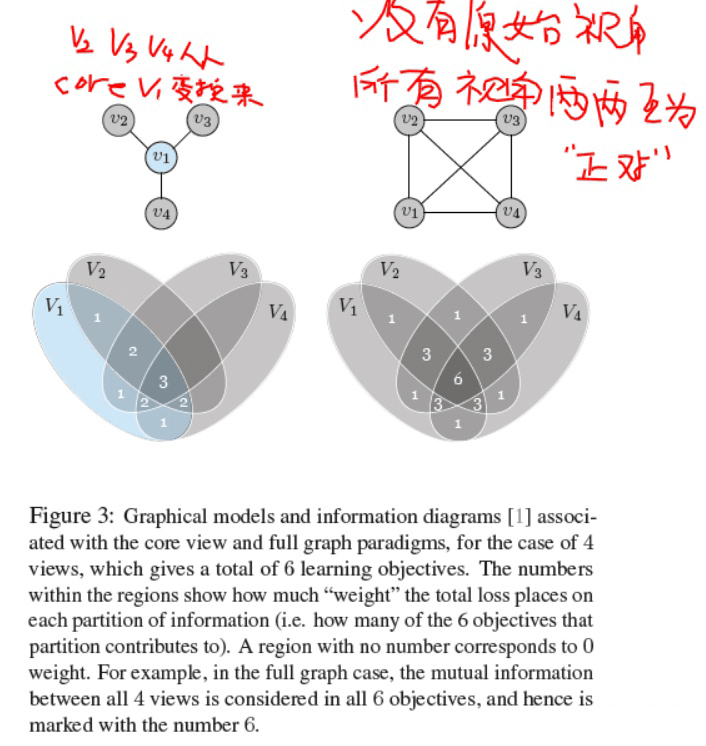
第一种:认为有一个主视角,其它视角都从这个视角变换而来。那么对比仅考虑主视角和“各”其它视角之间的对比。对应的损失如下(其中求和符号后面的就是常用的普通两视角对比损失)
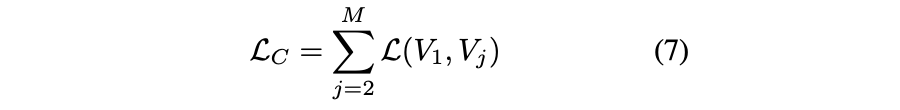
第二种,即便其它视角都从某一视角变换而来,也考虑所有视角 两两之间的对比。所以损失变成了
对比: 不同角度去看信号,看到的深层次结果应该一样。
DeepMind BYOL

论文标题:
Bootstrap your own latent: A new approach to self-supervised Learning
论文链接:
https://arxiv.org/pdf/2006.07733
代码链接:
https://github.com/deepmind/deepmind-research/tree/master/byol
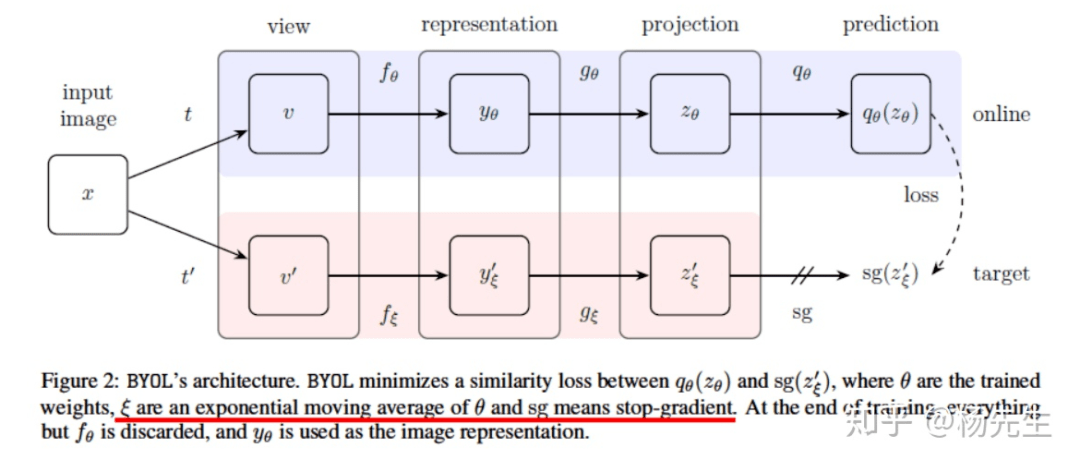
BYOL 核心思想很简单,用一个输入的两个视角作为输入,其中一个输入经 target 网络得到的输出作为 真值,去指导另一个 Online 网络的训练。然后下一次训练时将 Online Target 网络相互对调,依此往复。

另外 BYOL 也用到了 MOCO 中的利用网络参数的滑动平均来更新某一路网络。
SimSiam

论文标题:
Exploring Simple Siamese Representation Learning
论文链接:
https://arxiv.org/abs/2011.10566
首先这篇文章由于出来的靠后,所以对别人文文章的评价比较到位。


这篇文章网络结构就更简单了,就直接就是孪生网络,不做任何其它操作,只是阻断一下反向传播。
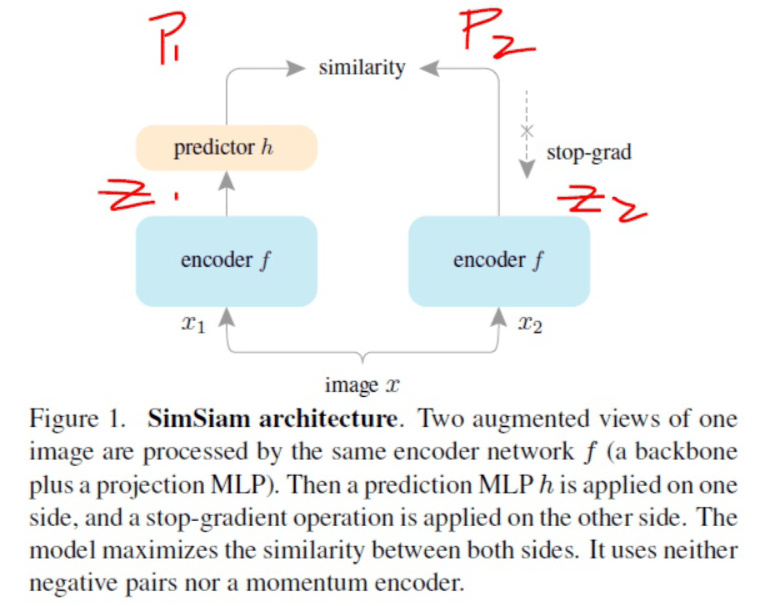
下面代码中 detach 就是将变量从反向传播网络中分离出来,只用它的数据。其作用就是阻断这个变量对前面参数更新的影响。

实际上通过 P 对网络参数的更新,间接也通过了 Z。也就是说,如果不阻断 Z 特征输出到网络参数的直接影响,那么相当于 Z 对参数的影响了两次。

阻断背后的 intuition 是什么?
文章的说法是:由于 Stop-gradient 的存在,相当于把 Z2 作为网络 1 的理想特征(类似于 K-means 里人为给每个特征分配一个不知道对不对的标签),而把 Z1 作为网络 2 的理想特征。所以文章的无监督学习变成了一个用 EM 求解理想特征的问题。
网络结构中有一分支为什么单独加了个Predictor
文章说是仅用了一个变换的特征作为理想特征去指导另一变换特征输出,严格上应该用多种变换的特征的平均值作为理想特征(就像 K-means 更新类中心的时候也是求平均), 所以作者说这个 Predictor 实际上是用来预测这个平均特征的。
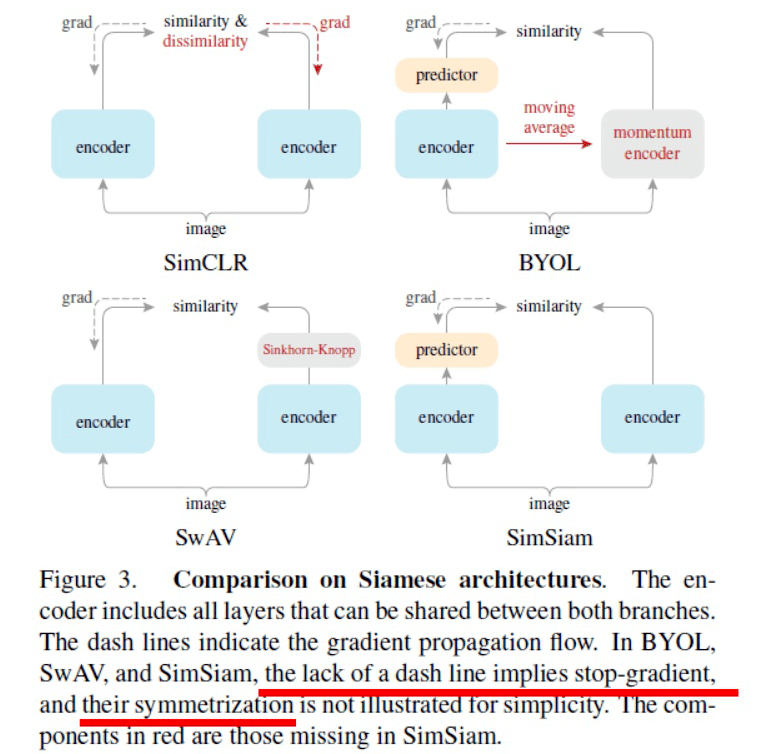
实际上,从作者最后画的图来看,这篇文章和 BYOL 非常之相似,只是两路网络参数是完全共享的。
清华组 PixPro
PixPro

论文标题:
Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning
论文链接:
https://arxiv.org/abs/2011.10043
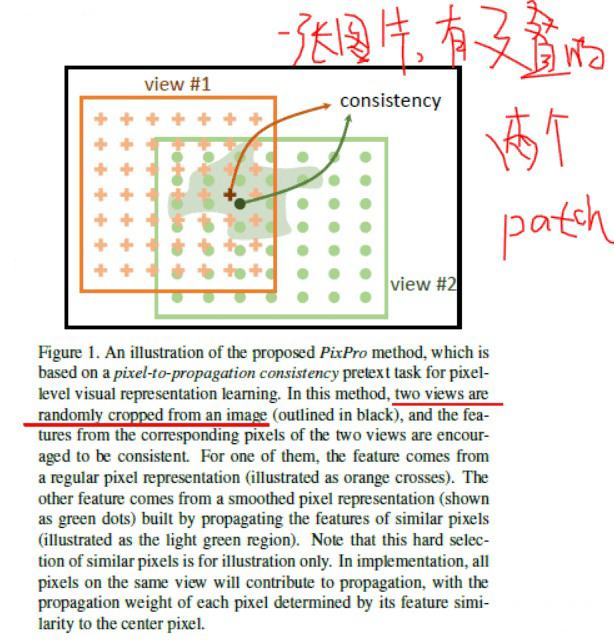
不同于以往用同一个 Patch 的两个变换做对比,本文用同一张图片,两个有交叠的 Patch 做对比, 交叠区域的像素特征应该相似。
• 稿件确系个人 原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)