原标题:在Juypter Notebook中构建联邦学习任务

题图摄于颐和园
(本文作者系 VMware 中国研发云原生实验室工程师,联邦学习 FATE / KubeFATE 开源项目贡献者。)
需要加入KubeFATE开源项目讨论群的同学,请关注本公众号后回复 “ kubefate” 即可。
概要
联邦学习开源框架 FATE 发布了1.5版本。由于该版本为长期支持版本(LTS),因此无论是在性能和稳定性上相对于之前的版本都有了比较大的提升,建议还没有升级的用户可以及时更新。
FATE 在 v1.5 有两个比较重要的改动,一个是可以使用 Spark 作为底层计算引擎;另一个则是提供了 “fate_client” 开发工具。后者在很大程度上方便了用户与FATE 集群的交互,本文将配合 Juypter Notebook 来着重介绍 “fate_client” 的使用。而对使用 Spark 作为底层计算引擎感兴趣的读者可以关注本系列文章,我们将会在后续文章中对其架构和使用进行介绍。
Jupyter Notebook 环境准备
对于使用 KubeFATE 来部署集群的用户来说,部署完成后通过 docker 或者 kubectl 命令列出容器时会发现一个名为 “client” 的容器。该容器是是一个 Jupyter Notebook 服务, 并且已经集成了“fate_client”,因此用户打开 Notebook 后可以直接使用相应的包与 FATE 集群进行交互。
Notebook 服务的访问方式根据部署方式而异,详情如下:
- docker-compose 方式部署:访问部署节点的20000端口,如192.168.0.1:20000。
- Kubernetes 方式部署:通过域名方式访问,如通过”9999.notebook.kubefate.net”来访问party 9999的notebook,域名的设置详情请参考”optional-add-kubefatenet-to-host-file”。
对于没有使用 KubeFATE 来部署集群的用户,则需要额外启动 Juypter Notebook服务和通过 pip 的方式安装”fate_client”。假设用户已经具备 python 3.7 环境则步骤如下:
$ pip install notebook fate-client
$ jupyter notebook –ip=0.0.0.0 –port=20000 –allow-root –debug –no-browser –NotebookApp.token= ”–NotebookApp.password= ”
上面的第二条命令会启动 Juypter Notebook 服务并监听 20000 端口,待服务启动完毕后则可以通过的方式 “IP:Port” 的方式访问 Notebook,下图展示通过浏览器访问 Notebook 服务。
通过 KubeFATE 部署的 Jupyter Notebook 自带了一些例子,这些例子是通过 fml_manager 来跟 FATE 集群进行交互的,在不久的未来 fml_manager 将与 fate_client 进行整合,因此本文不再详述。
FATE Client 简介
目前 fate_client 已经打包上传到了PyPI 上,因此可直接通过 pip install 的方式来安装。
从代码上来看其主要分为了三个部分,分别如下:
flow_sdk
这是对 fate_flow 所提供的 HTTP API 的一层封装,因此对于 FATE 中常用的数据结构如 job、component 等都有相应的操作,用户可以在代码中导入它来跟 FATE集群进行交互。一个通过 flow_sdk 来提交训练任务的例子如下:

上面的 Python 代码中通过FlowClient(‘127.0.0.1’, 9380, ‘v1’)初始化了与fate_flow的链接。
随后调用job.submit提交任务,任务的配置和DSL文件分别由conf_path 和dsl_path 指定。更多关于 flow_sdk 支持的操作可以参考 “flow_sdk/README.rst”。
flow_client
这个模块是在 fate_sdk 之上的一层封装,通过它可以直接以命令行的方式来跟FATE集群进行交互。
flow_client 在第一次使用时需要先进行初始化,需要指定 fate_flow 的地址,命令如下:

初始化只需要执行一次,完成后可以通过以下例子来提交任务:
$ flow job submit -c fate_flow/examples/test_hetero_lr_job_conf.json -d fate_flow/examples/test_hetero_lr_job_dsl.json
更多关于 flow_client 支持的指令可以参考” flow_client/README.rst“。
pipeline
此模块同样也是基于 fate_sdk 之上的一层封装,其最核心的功能是把FATE所有支持的算法都封装成了 python 中的类。以往任务的流程只能通过 json 文件去定义,但通过 pipeline 模块,用户可以通过代码以更加简洁和方便的方式去定义任务流程。
pipeline 最终会通过 flow_sdk 把任务提交到 FATE 集群上执行,因此它需要通过初始化来传递 fate_flow 的地址给 flow_sdk。一个初始化的例子如下:
$ flow init –ip 127.0.0.1 –port 9380 -d ./log
其中 -d指定了输出日志的路径。
使用 Pipeline 构建任务的具体例子可参考下一节,至于pipeline的更多详情可以参考 “pipeline/README.rst”。
在 Notebook 中定义并提交任务
接下来将通过一个例子来详细讲述如何通过 “Pipeline” 来定义和执行任务,下面用到的”usage_of_fate_client.ipynb”,用户可以自行下载并上传到 Notebook服务上使用。
Notebook 更改自 FATE 的 “pipeline-mini-demo.py”。
该例子按列把原数据集 “breast_cancer” 拆分了 “breast_hetero_guest” 和 “breast_hetero_host” 两部分,其中参与训练的 host 方持有不带标签的 “breast_hetero_host” ,而 guest 方则持有带有标签的 “breast_hetero_guest” 。随后 guest 和 host 将联合起来对数据集进行异构逻辑回归训练,最后当训练完成后还会使用模型执行离线推理任务。
为了简化,Notebook 的例子中只出现了一个 FATE 集群,该集群同时承担了guest 和 host 的角色。但在现实应用中,这两个角色应由不同的 FATE 集群担任。
对于不是通过 KubeFATE 来部署集群的用户来说,还需要依照上一节提到的方式为 “Pipeline” 进行初始化,反之只需要直接通过浏览器访问 Notebook 即可,无需进行初始化操作。为方便起见,以下访问的 Notebook 服务经由 KubeFATE 部署,其 party_id 为 10000。
下面每一步执行的日志都会输出到 Pipeline/logs目录下,用户可以很方便地通过 Notebook 查看。
上传数据
在FATE中执行训练任务需要把原数据集上传到集群中,并且需要指定(”namespace”, “name”)来作为其在系统中的唯一标识。在下面的代码中定义了 guest_train_data 和 host_train_data 两个数据集,并把原数据 “breast_hetero_guest.csv” 和 “breast_hetero_host.csv” 分别上传到对应的数据集当中。

定义训练组件
在下面的代码中首先用 guest_train_data、 host_train_data、 guest_eval_data、 host_eval_data指定了任务所需要用到的数据。在任务的 pipeline 通过 PipeLine初始化之后,使用 set_initiator和 set_roles来设定 guest 和 host 的相关信息。最后定义了 Reader、DataIO、Intersection 和 HeteroLR。其中 reader_0 和 reader_1 分别用于读取训练和验证的数据;dataio_0 和 dataio_1 用于把读取到的数据转为后续组件使用所需的格式;intersection_0 和 intersection_1分别用于求训练数据集和验证数据集的交集;hetero_lr_0 则定义了异构逻辑回归算法的具体参数。

构建训练流程并执行
这个代码段首先通过调用 add_component 把上一步定义的组件加入到了任务的pipeline 中,调用的顺序需要与组件的执行顺序一致。然后通过 compile 来验证和编译 pipeline,接着通过 job_parameters 来指定任务的计算引擎、工作模式等参数,最后调用 fit 来提交并运行任务。

定义并执行预测
预测的任务通过一个新的 pipeline 实例 predict_pipeline 来完成。在预测前需要通过 pipeline.deploy_component 来部署必要的组件,然后在 predict_pipeline 中使用。

预测的结果可以通过 FATEBoard 的来查看,结果如下:
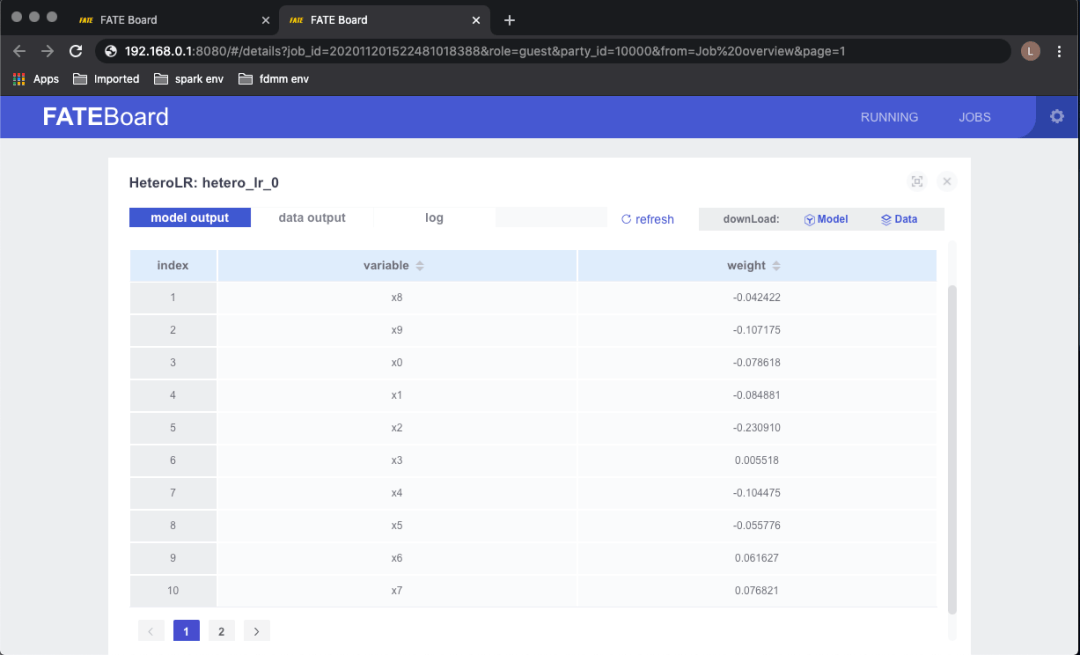
目前在 FATE 中已经自带了很多使用 “Pipeline” 的例子:examples/pipeline,感兴趣的读者可以把它们转换到 Notebook 里面来使用。
总结
相对与之前的版本,FATE v1.5 在各方面都有了比较大的提升,特别是在方便用户的使用上作出非常多的改进。本文只对其中一部分更新进行了介绍,对于更加详细的内容可以参考 FATE 的github代码 (https://github.com/FederatedAI/FATE/tree/v1.5.0) 和官方网站 (https://fate.fedai.org)。
原文链接:
https://github.com/FederatedAI/KubeFATE/wiki/%E5%9C%A8Juypter-Notebook%E4%B8%AD%E4%BD%BF%E7%94%A8FATE-Client%E6%9E%84%E5%BB%BA%E4%BB%BB%E5%8A%A1
需要加入KubeFATE开源项目讨论群的同学,请先关注本公众号,然后回复 “ kubefate ” 即可。