原标题:怎么用Redis分布式锁才能确保万无一失?

作者介绍
冷正磊,2018年2月加入去哪儿网 DBA 团队,主要负责机票业务的 MySQL 和 Redis 数据库的运维管理工作,以及数据库自动化运维平台部分功能的开发工作,对数据库技术具有浓厚兴趣,具有多年 MySQL 和 Redis 运维管理和性能优化经验。
一、背景
我们日常在电商网站购物时经常会遇到一些高并发的场景,例如电商 App 上经常出现的秒杀活动、限量优惠券抢购,还有我们去哪儿网的火车票抢票系统等,这些场景有一个共同特点就是访问量激增,虽然在系统设计时会通过限流、异步、排队等方式优化,但整体的并发还是平时的数倍以上,为了避免并发问题,防止库存超卖,给用户提供一个良好的购物体验,这些系统中都会用到锁的机制。
对于单进程的并发场景,可以使用编程语言及相应的类库提供的锁,如 Java 中的 synchronized 语法以及 ReentrantLock 类等,避免并发问题。
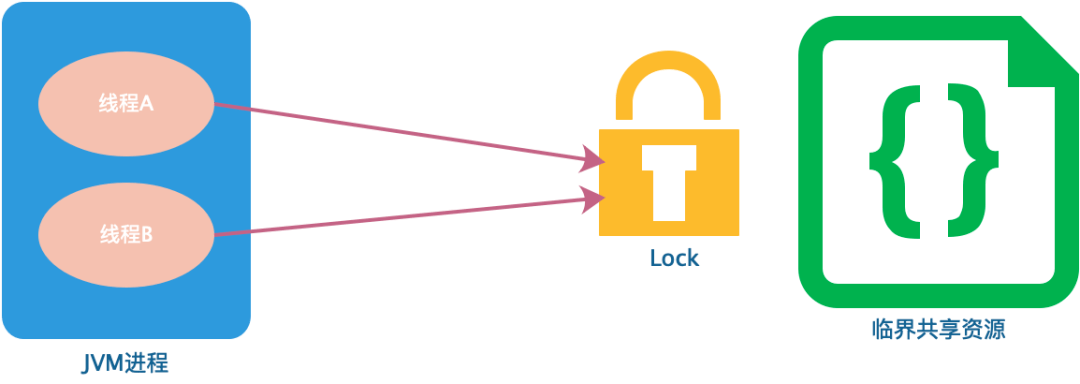
如果在分布式场景中,实现不同客户端的线程对代码和资源的同步访问,保证在多线程下处理共享数据的安全性,就需要用到分布式锁技术。
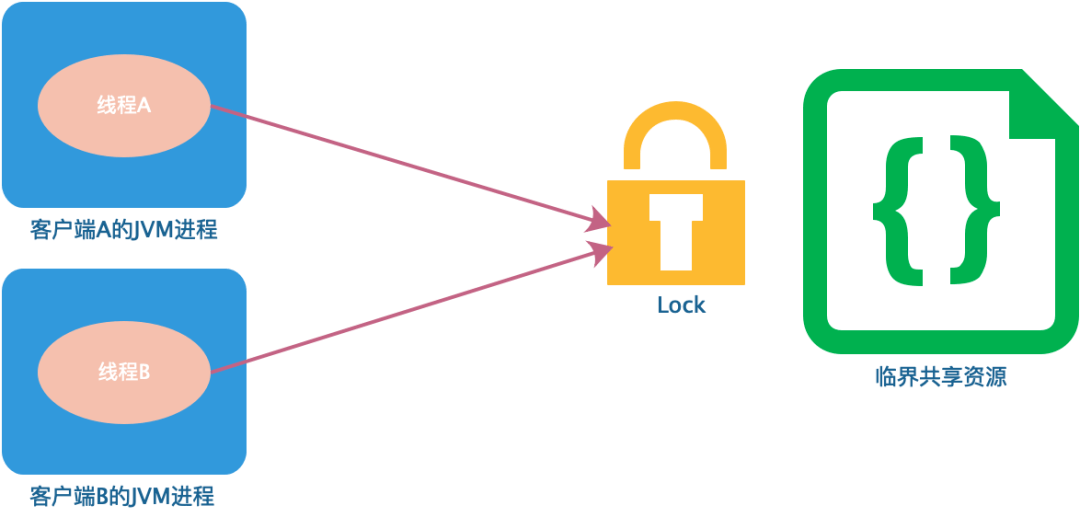
那么何为分布式锁呢?分布式锁是控制分布式系统或不同系统之间共同访问共享资源的一种锁实现,如果不同的系统或同一个系统的不同主机之间共享了某个资源时,往往需要互斥来防止彼此干扰保证一致性。
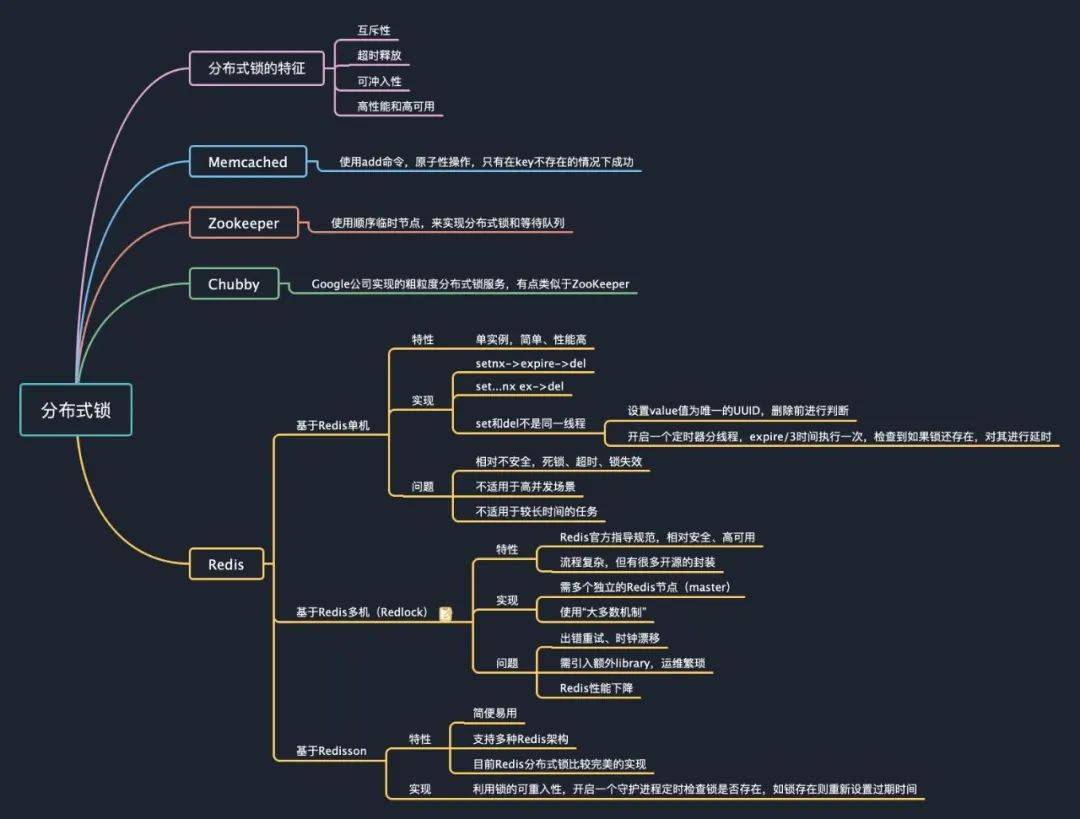
一个相对安全的分布式锁,一般需要具备以下特征:
- 互斥性。互斥是锁的基本特征,同一时刻锁只能被一个线程持有,执行临界区操作。
- 超时释放。通过超时释放,可以避免死锁,防止不必要的线程等待和资源浪费,类似于 MySQL 的 InnoDB 引擎中的 innodblockwait_timeout 参数配置。
- 可重入性。一个线程在持有锁的情况可以对其再次请求加锁,防止锁在线程执行完临界区操作之前释放。
- 高性能和高可用。加锁和释放锁的过程性能开销要尽可能的低,同时也要保证高可用,防止分布式锁意外失效。
可以看出实现分布式锁,并不是锁住资源就可以了,还需要满足一些额外的特征,避免出现死锁、锁失效等问题。
二、分布式锁的实现方式
目前实现分布式锁的方式有很多,常见的主要有:
- Memcached 分布式锁
利用 Memcached 的 add 命令。此命令是原子性操作,只有在 key 不存在的情况下,才能 add 成功,也就意味着线程得到了锁。
- Zookeeper 分布式锁
利用 Zookeeper 的顺序临时节点,来实现分布式锁和等待队列。ZooKeeper 作为一个专门为分布式应用提供方案的框架,它提供了一些非常好的特性,如 ephemeral 类型的 znode 自动删除的功能,同时 ZooKeeper 还提供 watch 机制,可以让分布式锁在客户端用起来就像一个本地的锁一样:加锁失败就阻塞住,直到获取到锁为止。
- Chubby
Google 公司实现的粗粒度分布式锁服务,有点类似于 ZooKeeper,但也存在很多差异。Chubby 通过 sequencer 机制解决了请求延迟造成的锁失效的问题。
- Redis 分布式锁
基于 Redis 单机实现的分布式锁,其方式和 Memcached 的实现方式类似,利用 Redis 的 SETNX 命令,此命令同样是原子性操作,只有在 key 不存在的情况下,才能 set 成功。而基于 Redis 多机实现的分布式锁Redlock,是 Redis 的作者 antirez 为了规范 Redis 分布式锁的实现,提出的一个更安全有效的实现机制。
本文主要讨论分析基于Redis的分布式锁的几种实现方式以及存在的问题。
三、Redis分布式锁
使用 Redis 作为分布式锁,本质上要实现的目标就是一个进程在 Redis 里面占据了仅有的一个“茅坑”,当别的进程也想来占坑时,发现已经有人蹲在那里了,就只好放弃或者等待稍后再试。
目前基于 Redis 实现分布式锁主要有两大类,一类是基于单机,另一类是基于 Redis 多机,不管是哪种实现方式,均需要实现加锁、解锁、锁超时这三个分布式锁的核心要素。
1、基于Redis单机实现的分布式锁
1)使用 SETNX 指令
最简单的加锁方式就是直接使用 Redis 的 SETNX 指令,该指令只在 key 不存在的情况下,将 key 的值设置为 value,若 key 已经存在,则 SETNX 命令不做任何动作。key 是锁的唯一标识,可以按照业务需要锁定的资源来命名。
比如在某商城的秒杀活动中对某一商品加锁,那么 key 可以设置为 lock_resource_id ,value 可以设置为任意值,在资源使用完成后,使用 DEL 删除该 key 对锁进行释放,整个过程如下:

很显然,这种获取锁的方式很简单,但也存在一个问题,就是我们上面提到的分布式锁三个核心要素之一的锁超时问题,即如果获得锁的进程在业务逻辑处理过程中出现了异常,可能会导致 DEL 指令一直无法执行,导致锁无法释放,该资源将会永远被锁住。
所以,在使用 SETNX 拿到锁以后,必须给 key 设置一个过期时间,以保证即使没有被显式释放,在获取锁达到一定时间后也要自动释放,防止资源被长时间独占。由于 SETNX 不支持设置过期时间,所以需要额外的 EXPIRE 指令,整个过程如下:

这样实现的分布式锁仍然存在一个严重的问题,由于 SETNX 和 EXPIRE 这两个操作是非原子性的, 如果进程在执行 SETNX 和 EXPIRE 之间发生异常,SETNX 执行成功,但 EXPIRE 没有执行,导致这把锁变得“长生不老”,这种情况就可能出现前文提到的锁超时问题,其他进程无法正常获取锁。

2)使用 SET 扩展指令
为了解决 SETNX 和 EXPIRE 两个操作非原子性的问题,可以使用 Redis 的 SET 指令的扩展参数,使得 SETNX 和 EXPIRE 这两个操作可以原子执行,整个过程如下:

在这个 SET 指令中:
- NX 表示只有当 lock_resource_id 对应的 key 值不存在的时候才能 SET 成功。保证了只有第一个请求的客户端才能获得锁,而其它客户端在锁被释放之前都无法获得锁。
- EX 10 表示这个锁10秒钟后会自动过期,业务可以根据实际情况设置这个时间的大小。
但是这种方式仍然不能彻底解决分布式锁超时问题:
- 锁被提前释放。假如线程 A 在加锁和释放锁之间的逻辑执行的时间过长(或者线程 A 执行过程中被堵塞),以至于超出了锁的过期时间后进行了释放,但线程 A 在临界区的逻辑还没有执行完,那么这时候线程 B 就可以提前重新获取这把锁,导致临界区代码不能严格的串行执行。
- 锁被误删。假如以上情形中的线程A执行完后,它并不知道此时的锁持有者是线程 B,线程A会继续执行 DEL 指令来释放锁,如果线程 B 在临界区的逻辑还没有执行完,线程 A 实际上释放了线程 B 的锁。
为了避免以上情况,建议不要在执行时间过长的场景中使用 Redis 分布式锁,同时一个比较安全的做法是在执行 DEL 释放锁之前对锁进行判断,验证当前锁的持有者是否是自己。
具体实现就是在加锁时将 value 设置为一个唯一的随机数(或者线程 ID ),释放锁时先判断随机数是否一致,然后再执行释放操作,确保不会错误地释放其它线程持有的锁,除非是锁过期了被服务器自动释放,整个过程如下:

但判断 value 和删除 key 是两个独立的操作,并不是原子性的,所以这个地方需要使用 Lua 脚本进行处理,因为 Lua 脚本可以保证连续多个指令的原子性执行。

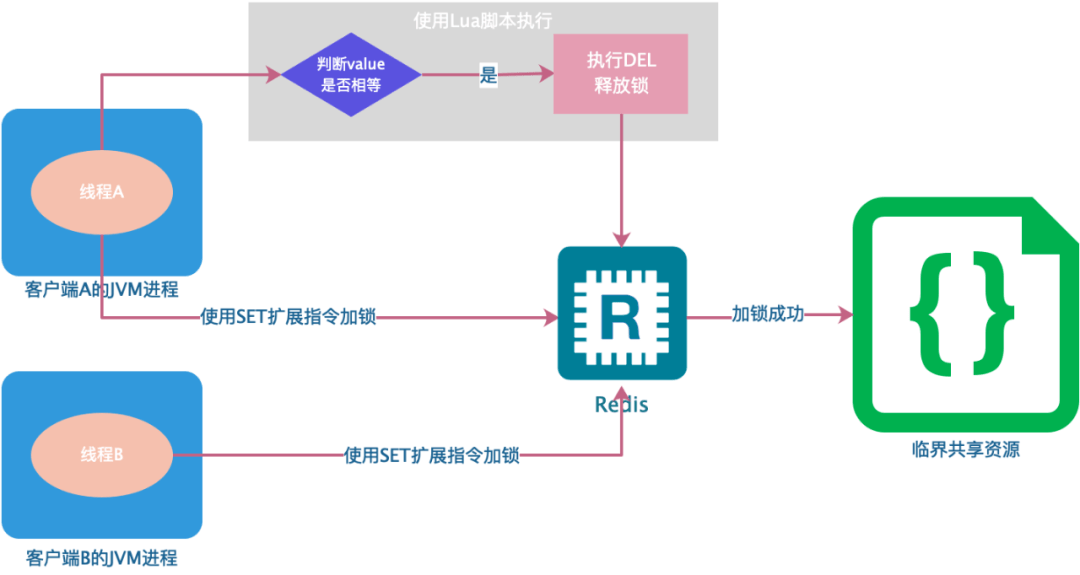
基于 Redis 单节点的分布式锁基本完成了,但是这并不是一个完美的方案,只是相对完全一点,因为它并没有完全解决当前线程执行超时锁被提前释放后,其它线程乘虚而入的问题。
3)使用 Redisson 的分布式锁
怎么能解决锁被提前释放这个问题呢?
可以利用锁的可重入特性,让获得锁的线程开启一个定时器的守护线程,每 expireTime/3 执行一次,去检查该线程的锁是否存在,如果存在则对锁的过期时间重新设置为 expireTime,即利用守护线程对锁进行“续命”,防止锁由于过期提前释放。
当然业务要实现这个守护进程的逻辑还是比较复杂的,可能还会出现一些未知的问题。
目前互联网公司在生产环境用的比较广泛的开源框架 Redisson 很好地解决了这个问题,非常的简便易用,且支持 Redis 单实例、Redis M-S、Redis Sentinel、Redis Cluster 等多种部署架构。
感兴趣的朋友可以查阅下官方文档或者源码:
https://github.com/redisson/redisson/wiki
其实现原理如图所示(图中以 Redis 集群为例):
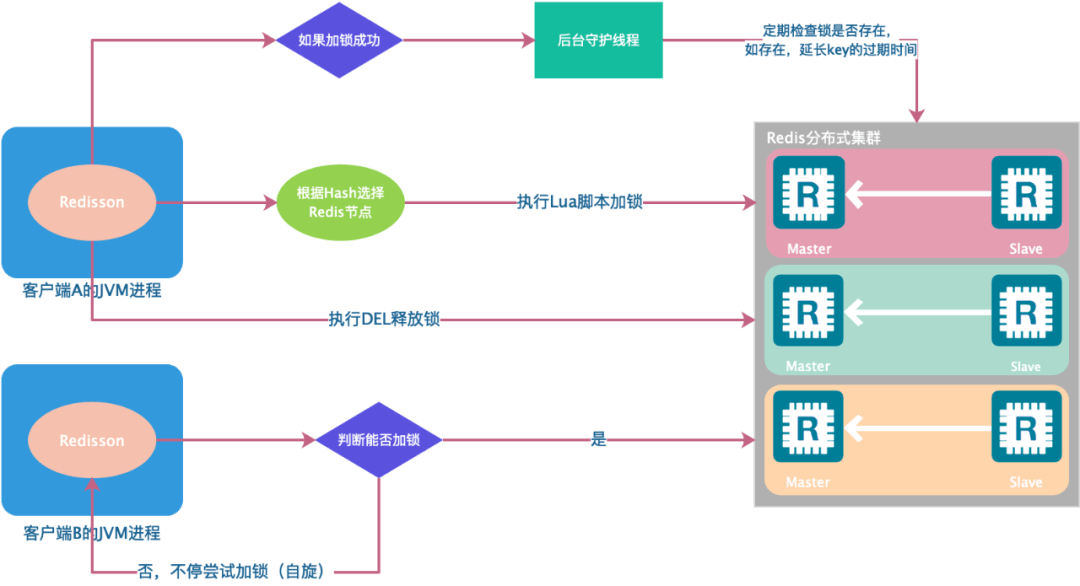
2、基于Redis多机实现的分布式锁Redlock
以上几种基于 Redis 单机实现的分布式锁其实都存在一个问题,就是加锁时只作用在一个 Redis 节点上,即使 Redis 通过 Sentinel 保证了高可用,但由于 Redis 的复制是异步的,Master 节点获取到锁后在未完成数据同步的情况下发生故障转移,此时其他客户端上的线程依然可以获取到锁,因此会丧失锁的安全性。
整个过程如下:
- 客户端 A 从 Master 节点获取锁。
- Master 节点出现故障,主从复制过程中,锁对应的 key 没有同步到 Slave 节点。
- Slave升 级为 Master 节点,但此时的 Master 中没有锁数据。
- 客户端 B 请求新的 Master 节点,并获取到了对应同一个资源的锁。
- 出现多个客户端同时持有同一个资源的锁,不满足锁的互斥性。
正因为如此,在 Redis 的分布式环境中,Redis 的作者 antirez 提供了 RedLock 的算法来实现一个分布式锁,该算法大概是这样的:
假设有 N(N>=5)个 Redis 节点,这些节点完全互相独立,不存在主从复制或者其他集群协调机制,确保在这N个节点上使用与在 Redis 单实例下相同的方法获取和释放锁。
获取锁的过程,客户端应执行如下操作:
- 获取当前 Unix 时间,以毫秒为单位。
- 按顺序依次尝试从5个实例使用相同的 key 和具有唯一性的 value(例如 UUID)获取锁。当向 Redis 请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间。例如锁自动失效时间为10秒,则超时时间应该在5-50毫秒之间。这样可以避免服务器端 Redis 已经挂掉的情况下,客户端还在一直等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试去另外一个 Redis 实例请求获取锁。
- 客户端使用当前时间减去开始获取锁时间(步骤1记录的时间)就得到获取锁使用的时间。当且仅当从大多数(N/2+1,这里是3个节点)的 Redis 节点都取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功。
- 如果取到了锁,key 的真正有效时间等于有效时间减去获取锁所使用的时间(步骤3计算的结果)。
- 如果因为某些原因,获取锁失败(没有在至少N/2+1个 Redis 实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的 Redis 实例上进行解锁(使用 Redis Lua 脚本)。
释放锁的过程相对比较简单:客户端向所有 Redis 节点发起释放锁的操作,包括加锁失败的节点,也需要执行释放锁的操作,antirez 在算法描述中特别强调这一点,这是为什么呢?
原因是可能存在某个节点加锁成功后返回客户端的响应包丢失了,这种情况在异步通信模型中是有可能发生的:客户端向服务器通信是正常的,但反方向却是有问题的。虽然对客户端而言,由于响应超时导致加锁失败,但是对 Redis节点而言,SET 指令执行成功,意味着加锁成功。因此,释放锁的时候,客户端也应该对当时获取锁失败的那些 Redis 节点同样发起请求。
除此之外,为了避免 Redis 节点发生崩溃重启后造成锁丢失,从而影响锁的安全性,antirez 还提出了延时重启的概念,即一个节点崩溃后不要立即重启,而是等待一段时间后再进行重启,这段时间应该大于锁的有效时间。
关于 Redlock 的更深层次的学习,感兴趣的朋友可以查阅下官方文档:https://redis.io/topics/distlock
四、总结
分布式系统设计是实现复杂性和收益的平衡,既要尽可能地安全可靠,也要避免过度设计。Redlock 确实能够提供更安全的分布式锁,但也是有代价的,需要更多的 Redis 节点。在实际业务中,一般使用基于单点的 Redis 实现分布式锁就可以满足绝大部分的需求,偶尔出现数据不一致的情况,可通过人工介入回补数据进行解决,正所谓“技术不够,人工来凑”!。
作者丨冷正磊
来源丨公众号:Qunar技术沙龙(ID:QunarTL)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:[email protected]