原标题:DTCC 2020 | 阿里云王涛:阿里巴巴电商数据库上云实践
简介: 第十一届中国数据库技术大会(DTCC2020),在北京隆重召开。大会以“架构革新 高效可控”为主题,重点围绕数据架构、AI与大数据、传统企业数据库实践和国产开源数据库等内容展开分享和探讨。在数据库智能运维专场上,邀请了阿里云数据库高级技术专家王涛为大家介绍阿里巴巴电商数据库上云的选择、思考与实践。阿里巴巴电商数据库原先是在自己独立的IDC维护的,伴随着阿里巴巴上云项目,数据库轻松实现上云。阿里云云原生管控以及云原生数据库技术可以帮助业务实现平滑上云目标,进而实现资源最大化成本最优化的目标。阿里巴巴希望利用阿里云的技术体系,帮助客户大规模上云,打造自己的运维管控平台。

演讲嘉宾简介:
王涛,阿里云数据库高级技术专家,来自阿里云数据库产品事业部,喜欢并热爱数据库。
职业生涯:程序员->DBA->DevOps架构师。2007年开始参与、设计、主导了阿里巴巴数据库体系演进,主导参与了阿里巴巴数据库体系演进,经历了数据库去IOE,规模化MySQL运维,阿里数据库异地多活,数据库上云等多个核心项目。目前为阿里云RDS管控负责人,为大家提供安全、稳定、经济、智能的数据库服务。
本次分享主要围绕以下四个方面:
一、阿里巴巴电商数据库应用场景介绍
二、数据库管控平台演进
三、数据库上云的选择与思考
四、未来展望
一、阿里巴巴电商数据库应用场景介绍
1. 阿里业务特性介绍 —— RDS三节点企业版
什么是阿里巴巴电商数据呢?大家看到的淘宝、天猫、盒马、饿了么上的数据都属于阿里巴巴电商数据,这些业务说使用的数据库目前都在云上。阿里巴巴之前的数据库是RDS高可用版,采用一主多备模式,但是发现实例无法做到RPO为零。尝试使用了MySQL半同步等措施,但依然无法解决RPO为零的问题。其次是考虑采取CAP理论或者BASE理论的问题。CAP指的是一致性(Consistency)、可用性(Availability)、分区容忍性(Partition tolerance)。但事实上数据库是无法做到同时满足CAP中的三点特性的,只能满足其中一到两项。对于BASE理论大家或许不太熟悉,其核心在于可以做到中间不一致,A和B机器可能单独的时候不一致,但是一旦连上之后就会一致。数据管控系统上通常遵守BASE理论,数据库更多的时候是选择CAP原理。解决RPO等于0的问题有几种实现方式,首先是MySQL半同步、还有MySQL Group Replication,这是MySQL 5.7版本之后推出的新功能,但是要求三份数据一样,这个成本是无法接受的。因此阿里逐渐走向了RDS自研的方向。
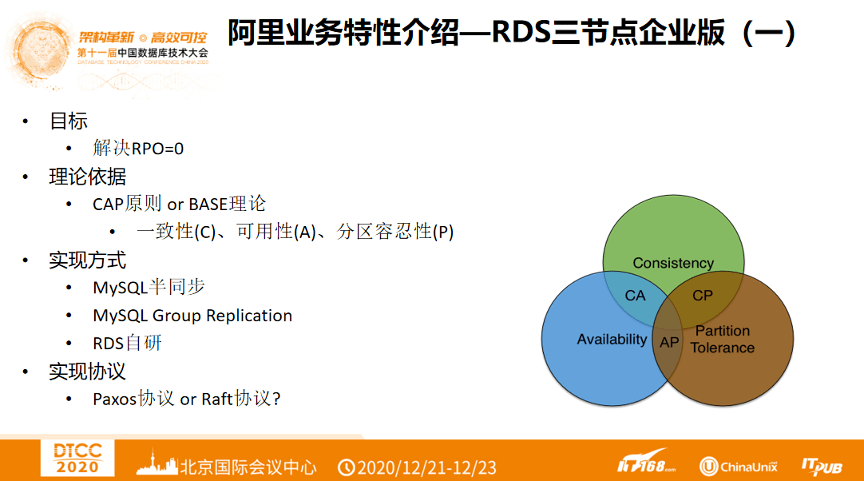
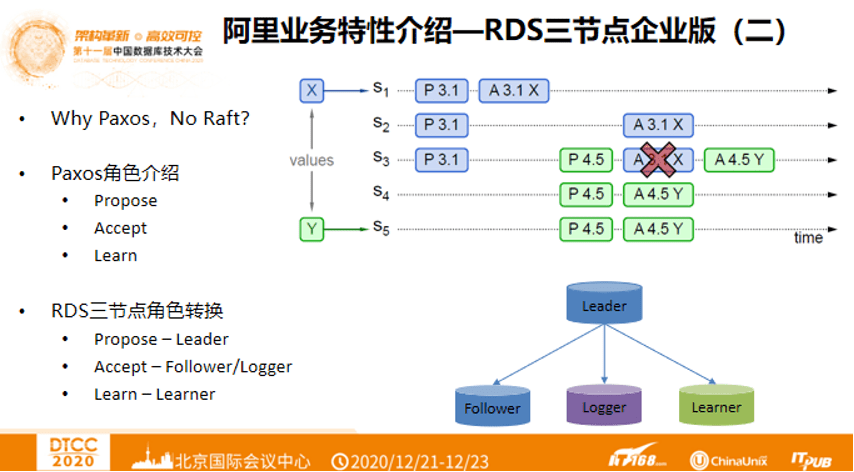
阿里巴巴在选择数据库协议也是在Paxos协议 or Raft协议中徘徊,最终选择了Paxos协议。
阿里巴巴在选择数据库协议也是在Paxos协议 or Raft协议中徘徊,最终选择了Paxos协议。Why Paxos,No Raft? 从下图右侧可以看到前面都在提交数据X、后面来了数据Y,在S3中先执行了P3.1,P4.5,A4.5 Y,这意味着Paxos协议不一定要有序,而Raft是有序的。Raft协议会要求S3先执行P3.1、A 3.1 X然后再执行P4.5,A 4.5 Y。这是Paxos协议和 Raft协议最大的不同。其次,Paxos协议有三种角色,提交者(Propose),接收者(Accept)以及Learn。阿里巴巴自研的RDS对这三种角色进行了转化,Propose叫做Leader,指的是可读可写的数据库节点,Accept叫做Follower,多数派,有全量的数据,可以将自己变成Leader。还有Logger(阿里自研角色),只负责接收日志,没有数据。Leader和Follower有全量数据,Logger只是日志接收节点,如此CPU和内存成本就会降低。Learn叫做Learner,属于观察者角色,有全量数据但没有投票权,即使Learner挂掉,也不会影响Learner多数提交。
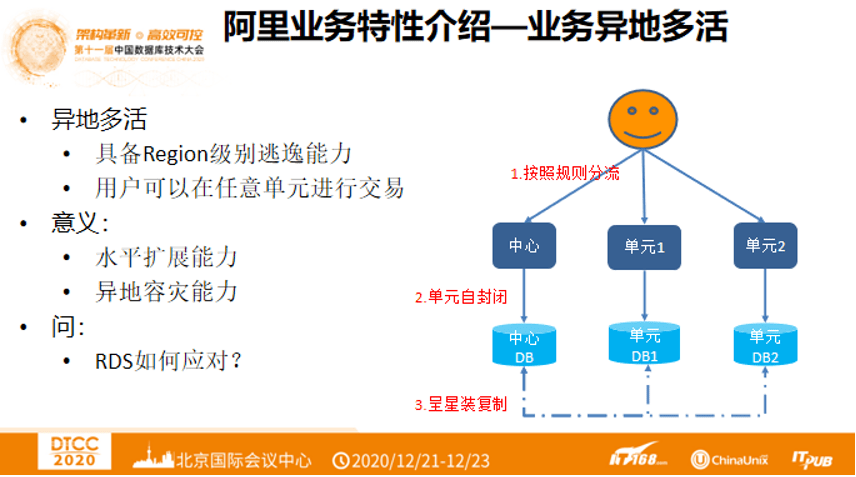
2. 阿里业务特性介绍 —— 异地多活
众所周知,阿里巴巴的业务还有一个特性,就是异地多活。异地多活有两点好处,都是可以具备Region级别逃逸能力,用户可以在任意单元进行交易。下图右侧是User通过规则分流,在数据中心及其它单元都可以进行交易。异地多活可以做到水平扩展和异地容灾,在每年的双11可以临时建立站点,在9月份建好,在双11之后2周撤掉。
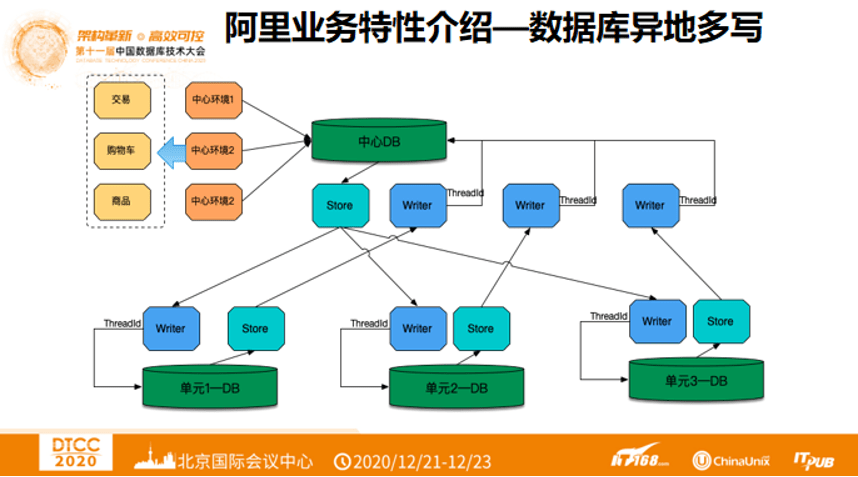
3. 阿里业务特性介绍 —— 数据库异地多写
那么RDS如何应对异地多活?异地多活意味着异地多写。下图展示了支持异地多活的数据库分布情况,首先要有一个中心DB,对应多个中心环境,分别是交易、购物车、商品等。中心数据库写的数据会到对应的Store,Store可以避免调多个线程时影响数据库性能的问题。Writer负责将数据写到对应的单元DB。单元DB中的数据通过Store回到中心的Writer,回到中心DB。可以发现数据的push呈现星状,而不是网状,这是出于几点考虑,首先很难做DTL,大家都在做DTL,很容易被复制;其次,星状结构可以至少保证一个节点数据是全局一致的,哪怕单元DB挂掉,在中心DB中也有全量数据。
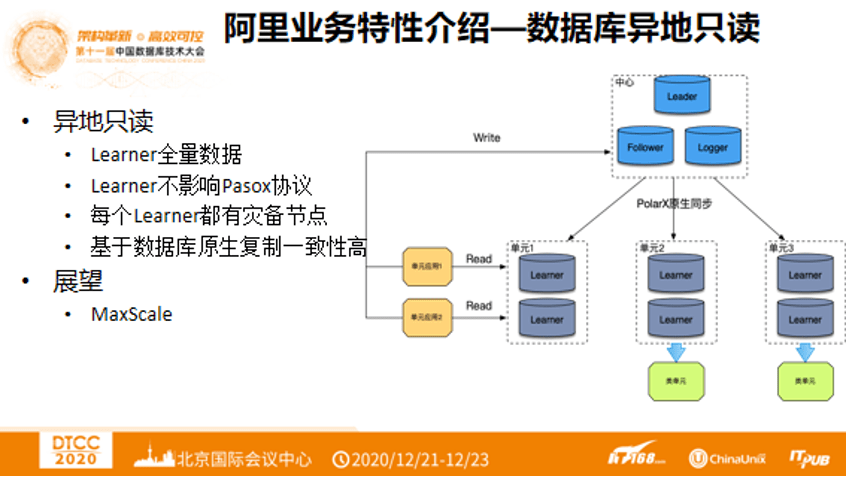
4. 阿里业务特性介绍 —— 数据库异地只读
阿里业务特性使得数据库需要有支持异地只读的特性。Learner节点,具备全量数据,不影响Paxos协议,每个Learner节点都要灾备节点。基于数据库原生复制一致性高。要保证MySQL内部数据的一致性。因此数据库架构会如下图右侧所示,中心有三种节点:Follower、Logger、Learner,它们之间可以互相切换。每个单元有Learner节点和备用的Learner节点,单元应用也在单元Learner中。假设要做一级容灾,那么可以将单元写权重路由到中心,通过中心再Put到各个单元中,如此不仅可以做的全局一致性还可以做到异地多写。
二、数据库管控平台演进
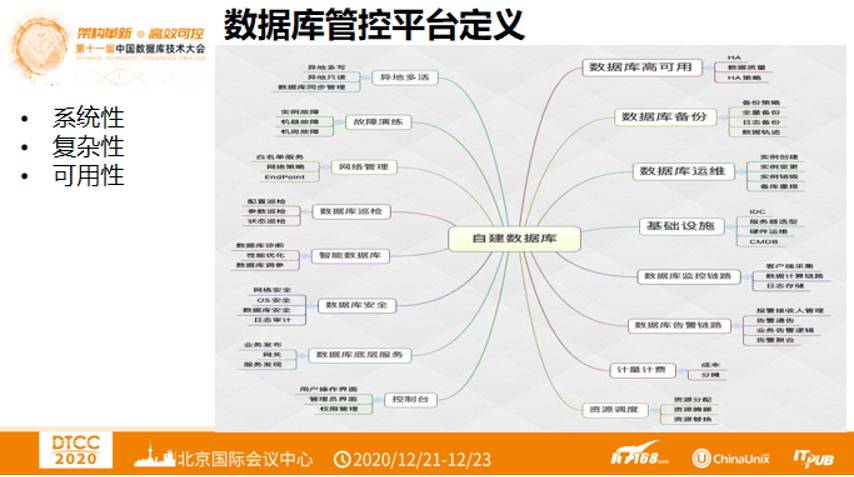
1. 数据库管控平台定义
大家往往会误以为做数据库管控就是做数据库运维,但事实上并不是那么简单。数据库管控要做的事情有非常多:
首先,数据库高可用是独立的模块,业界常用的有HA策略;数据备份,业界有备份策略,如全量备份、日志备份、数据轨迹备份等;数据库运维包括实例创建、实例变更、实例销毁、备库重大搭等;建设基础设施,如IDC、服务器选型、硬件运维、CMDB;数据库监控链路和数据告警链路两个不同的模块;还有数据库的计量计费;资源调度;控制台;数据库底层服务,如网关、服务发现等;数据库安全;智能数据库,如数据库智能诊断、数据库智能调参、性能调优等,也是目前主要的一个模块;数据巡检,如配置、参数、状态巡检;网络管理;故障演练;异地多活等等。
可以发现,即使粗略的罗列完数据库管控平台包含的内容,也会非常多的模块,这导致平台的系统性、复杂性都很高,由于对数据库的依赖性很高,必然造成对其可用性的要求的提升。那么这些要求应该如何满足?
2. 阿里巴巴数据库管控平台演进
阿里巴巴的数据库管控平台也是经历了若干代前辈的努力:
1) 2003年,当时并没有DBA这个职业。阿里从SA(系统管理员)团队拆出了一位同学做DBA,属于纯人工运维。
2) 2006年,开始使用业界流行的Nagios、Cacti等开源工具。
3) 2009年,阿里开始自研,自主研发了第一代运维系统“北斗”,替换了Nagios、Cacti等开源工具。
4) 2010年,阿里巴巴开始进行去IOE工作,加速了管控的规模化运维,阿里第一代MySQL运维系统诞生,“天机”。主要面向监控、可用性、备份。属于单体应用。
5) 2013年,随着业务规模不断扩大,阿里第二代MySQL运维系统诞生,“DBFree”。主要面向自动化运维。
6) 2016年,阿里第三代数据库运维系统“DBPaaS”诞生,满足异地多活、混合云等业务需求。
7) 2018年,底层IaaS上云,使用云资源。
8) 2020年,阿里电商数据库全面开始上云,开始使用云管控。所有核心数据库(交易、购物车、商品、优惠等)及核心链路都采用云数据库专属集群(MyBase)模式。基于云原生数据库,构建了上万个节点,实现了RPO=0。
数据库上云的选择与思考
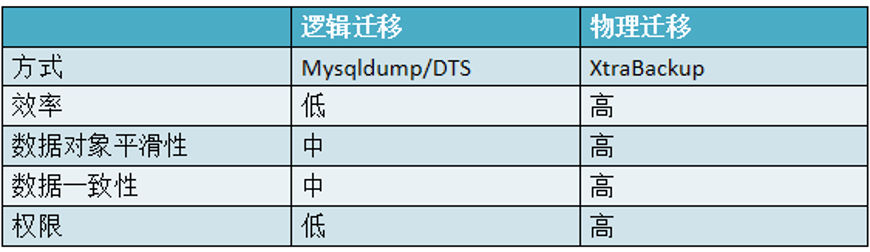
1. 上云方案选择 —— 数据上云方案选择
数据上云方案有很多选择。首先是数据上云方式的选择,是使用逻辑迁移还是物理迁移?下图这两种数据上云方式的对比,绝大多数迁移都是逻辑迁移,使用的是MySQL/DTS的方式。但是阿里巴巴的业务特性导致数据规模的体量巨大,需要使用物理迁移,XtraBackup云原生物理迁移。上云之后在2020年12月底,MyBase会推出物理机房push的上云模式。从下图可以发现迁移的效率、数据对象平滑线、数据一致性、权限等相比于逻辑迁移都是较高的。对于小规模数据上云时逻辑迁移是足够的,但是大规模体量下,物理迁移更合适。
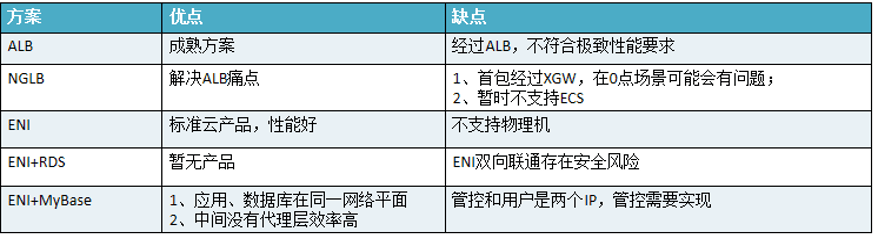
2. 上云方案选择 —— 网络方案选择
在网络方面也有几种选择,首先是ALB,它最好的优点是相对成熟,但是也存在很明显的缺点,就是所有的包都要经过ALB,这不符合极致性能要求。NGLB,可以解决ALB的痛点,只有首包经过XGW,后面的包不需要经过。但是在0点场景中,NGLB的确是扛不住的。NGLB也不支持ECS。ENI(弹性网卡),业界主推的弹性网卡方案。但是弹性网卡方案依然有个问题,就是不支持物理机。这使得阿里巴巴又往ENI+RDS走了一步,但是目前还没有计划推出这个产品,而且由于网卡都是双向联通的,会存在安全风险。阿里目前使用的是ENI+MyBase方案,此方案的优点是应用和数据库在同一个网络平面,中间没有代理层,效率较高。但对于管控而言,复杂度提升了不少。一个机器上有两块网卡,用户用到的网卡和物理机网卡。机器不得不做两次操作,分别是数据链路和管控链路。考虑到数据需要双向联动和性能问题,所以使用了ENI,又考虑到安全性问题,使用了ENI+MyBase方式。
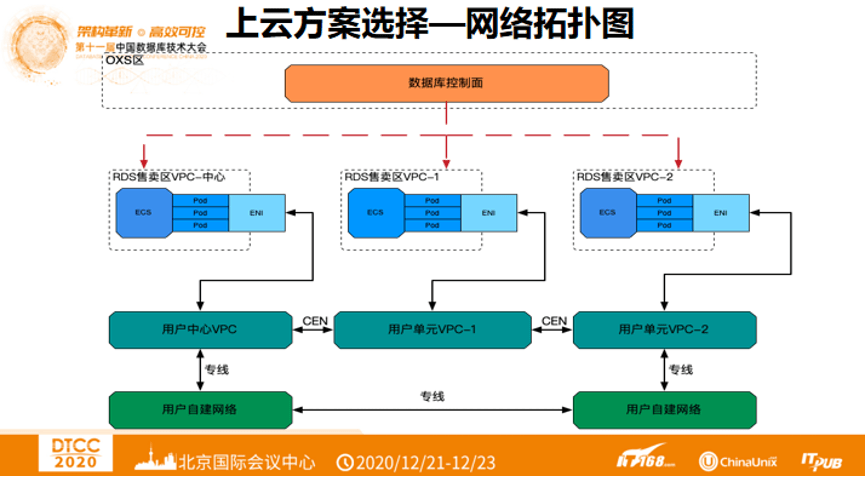
3. 上云方案选择 —— 网络拓扑图
如下图,最上层是数据库管控平面,下一层是RDS售卖区VPC,用户中心VPC与用户单元VPC之间通过CEN打通,使得全链路打通,这里使用了阿里云产品支撑整个云上架构。在云下,支持用户自建网络,通过专线打通用户自建网络与用户中心VPC,用户单元VPC。用户自建网络之间通过专线打通。保证整个数据库在用户之间是联通的。
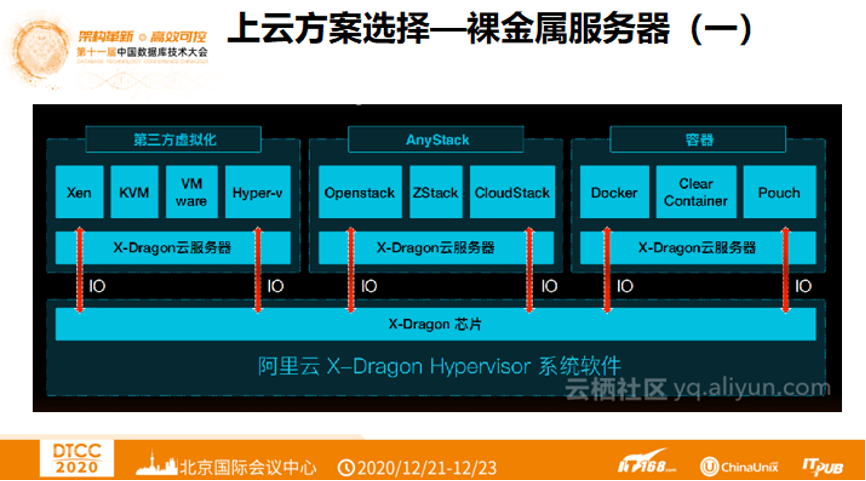
4. 上云方案选择 —— 裸金服务器
阿里巴巴没有使用普通的金属服务器,而是使用了裸金服务器。它们之间区别在于裸金服务
器最下层有一个叫做X-Dragon芯片,也叫MOC卡。机器本身是耗费资源的,但使用“神龙”服务器以后可以完全剥离掉这部分,就是说如果买了96C,768G的机器,那么就是这么多的资源,不会再因为虚拟化的成本带来额外的开销。MOC卡还有一个作用是上层的组件,如VPC/SLB、EBS云盘都会经过MOC卡进行虚拟化,大大减少其它开销,也就是把一台机器变成和虚拟机一样的用户体验。
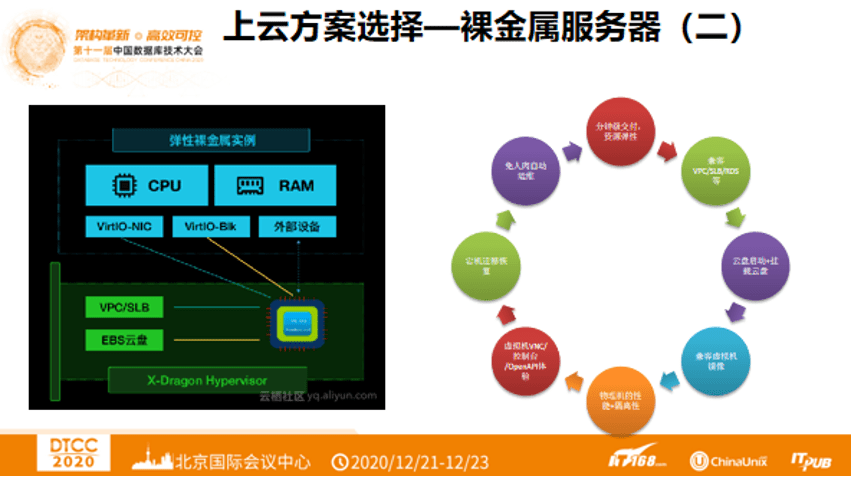
使用X-Dragon架构可以分钟级的去创建100%物理机性能和功能的云服务器,兼容VPC、SLB、RDS,支撑云盘启动和挂载云盘,兼容虚拟机镜像,保证物理机的性能和隔离性,。免去了人肉自动运维的事情。使用ECS还可以在宕机后,10分钟内原地拉起一台数据库,迁移恢复。
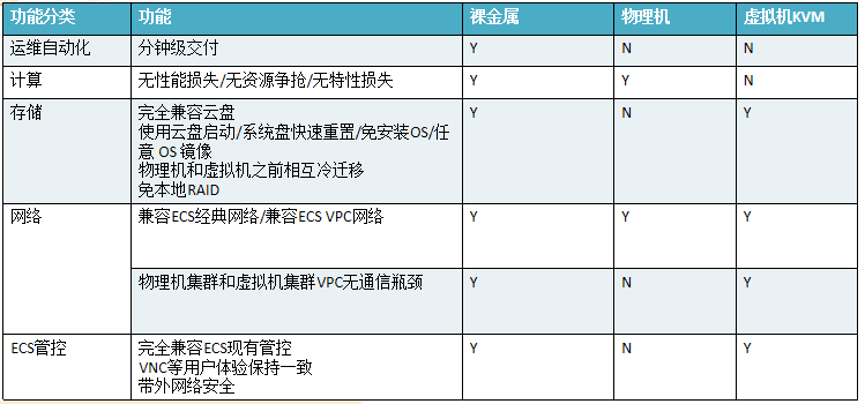
基于下图中几方面的考虑,在对比了物理机,虚拟机KVM,裸金属服务器ECS之后,阿里巴巴选择了裸金属服务器。运维自动化方面裸金属服务器支撑分钟级交付。使用MOC卡机器是无损耗的。在存储方面,裸金属服务器操作系统使用了云盘,可以快速重置系统盘。在网络方面,物理机部分支持网络一致性。裸金属服务器方案和虚拟机都兼容ECS现有管控。
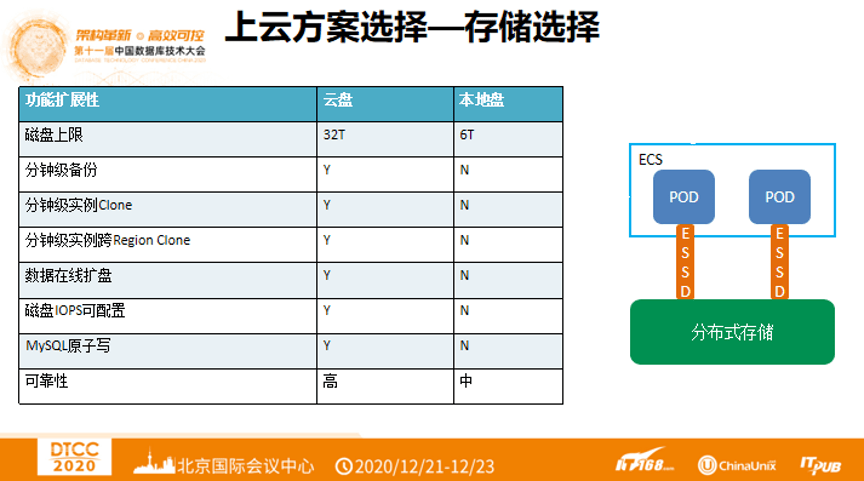
上云方案选择 —— 存储选择
下面简单讨论一下存储为何使用云盘?原来云盘最大的上限是16T,现在这个值已经变成了32T,基本可以满足99%以上用户的数据库需求,而物理机可能最多只有6T。云盘可以支持分钟级备份,而之前的方法迁移1T数据就需要3个小时。云盘分钟级实例Clone、分钟级实例跨Region Clone、数据在线扩盘。运维人员在设置数据库的性能时非常头疼,没有可选的办法,云盘可支持磁盘IOPS可配置,意味着可以运维人员强制设置数据库IO吞吐,目前最高的吞吐是500MB/秒。MySQL有double write的特性,云盘支撑MySQL原子写,少了一次write的开销。可靠性方面物理机总是没有分布式存储高。一个ECS,里面是POD,拉起一个容器,使用ESSD存储,最下面是分布式存储。
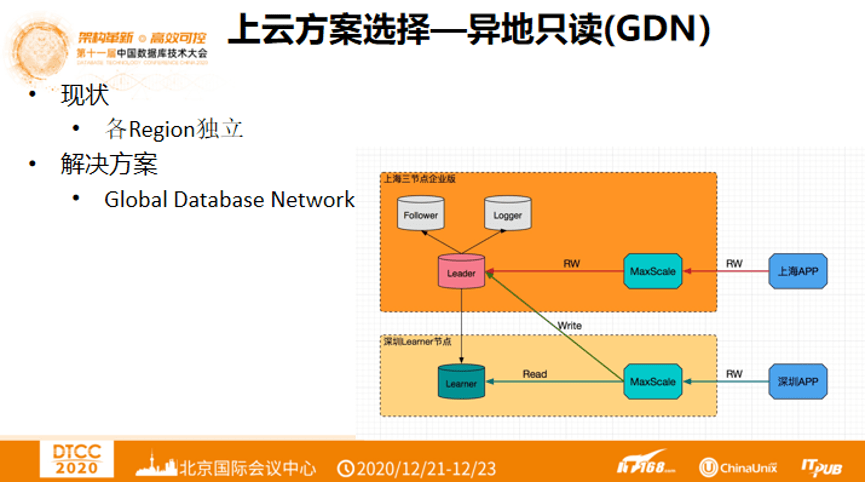
上云方案选择 ——异地只读(GAN)
目前阿里云还没有开放异地只读的上云特性。阿里巴巴希望做到各个Region独立,主要是基于Global Database Network解决方案。上海的APP通过MaxScale到上海的数据库,同理,深圳的APP通过MaxScale一部分分流到原生的数据库Leader中,一部分到深圳的数据库,从而实现异地多写。
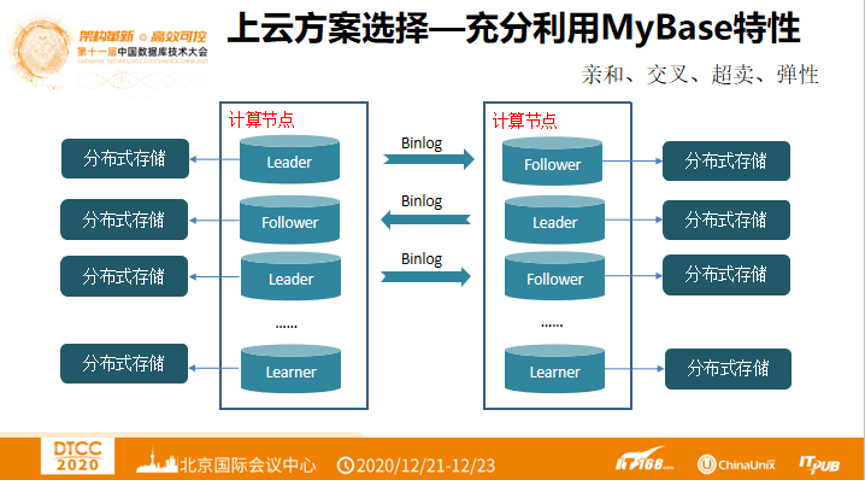
7. 上云方案选择 —— 充分利用MyBase特性
为什么使用MyBase? 如下图,买了一对云主机,左侧备份几个Leader,几个Follower,右侧同理。节点之间做到亲和、交叉、超卖、弹性。MyBase可以做到交叉,两主两备,性能最好,其次是亲和,购物车的数据和其它数据库在一起,但又互相独立。因为业务特性需要进行临时扩容,这种情况非常常见,而MyBase可以做到动态的调参。因为底层使用了云盘,可以满足弹性需求。
8. 上云的方案9大特性
总结而言,上云的方案分别要满足以下9个特性:
高可用:数据库主备架构,高可用性保障,宕机自动切换、修复。
高可靠:数据库多副本保障、数据同步可调一致性保障(RPO优先)、三节点企业版RPO=0保障。
高性能:内核性能提升,相比开源版本MySQL(1.5x)Redis(3x)。
高安全:SSL链路加密、TDE落盘加密、审计日志体系等。保障事前,事中,事后的数据库安全。
运维能力:备份恢复、监控报警、智能运维诊断等全套数据库运维解决方案。
自主可控:开放OS、数据库完整权限;开放数据库管控平台标准化底层接口;用户可深度自定义数据库管理逻辑。
混部:混合部署MySQL、Redis等,并提供云数据库管理特性。
资源调度:用户专属一片物理主机资源池,可自定义实例分配、分布策略,高度适配业务需求。
超配能力:用户物理资源100%隔离,支持CPU、内存(Redis)、空间等资源的超配。
数据库上云是出于几点考虑,首先自建数据库不支持很多的数据库管控平台特性,RDS支持部分特性,如弹性网卡等。而MyBase是在RDS基础之上衍生出来的产品,目前基本都可以支持这9个特性。

四、总结及未来展望
1.上好云,用好云
阿里巴巴数据库上云是考虑到业务本身场景,还有云原生技术,以及促进阿里云内部改造等原因。目前2020年双11期间交易额达到了4982亿,高峰订单58.3万笔/秒,云原生数据库可以很平滑的支持这些业务。阿里巴巴电商数据库上云不仅仅是把数据库搬上云,更多的思考是如何上好云,用好云。为了支持阿里巴巴的业务,阿里云内部做了很多的改造。通过使用阿里云云原生管控以及云原生数据库技术帮助业务实现平滑上云目标,进而实现资源最大化成本最优化的目标。
2. 未来展望
数据库上云会经历几个大的阶段。最早是物理机阶段,之后是存计分离,阿里巴巴在2016年就开始存计分离,之后到现在的MyBase形态。相信之后在多样性方面会有很多发展,未来不仅仅使用MySQL这一种数据库,还会有很多OLTP的数据库。最后,数据库的智能化一定是未来的大趋势。

作者:stromal