原标题:阿里云 EMR Delta Lake 在流利说数据接入中的架构和实践
简介: 为了消灭数据孤岛,企业往往会把各个组织的数据都接入到数据湖以提供统一的查询或分析。本文将介绍流利说当前数据接入的整个过程,期间遇到的挑战,以及delta在数据接入中产生的价值。
背景
流利说目前的离线计算任务中,大部分数据源都是来自于业务 DB,业务DB数据接入的准确性、稳定性和及时性,决定着下游整个离线计算 pipeline 的准确性和及时性。同时,我们还有部分业务需求,需要对 DB 中的数据和 hive 中的数据做近实时的联合查询。
在引入阿里云 EMR Delta Lake 之前,我们通过封装 DataX 来完成业务 DB 数据的接入,采用 Master-Slave 架构,Master 维护着每日要执行的 DataX 任务的元数据信息,Worker 节点通过不断的以抢占的方式获取状态为 init 和 restryable 的 DataX 任务来执行,直到当天的所有的 DataX 任务全都执行完毕为止。
架构图大致如下:
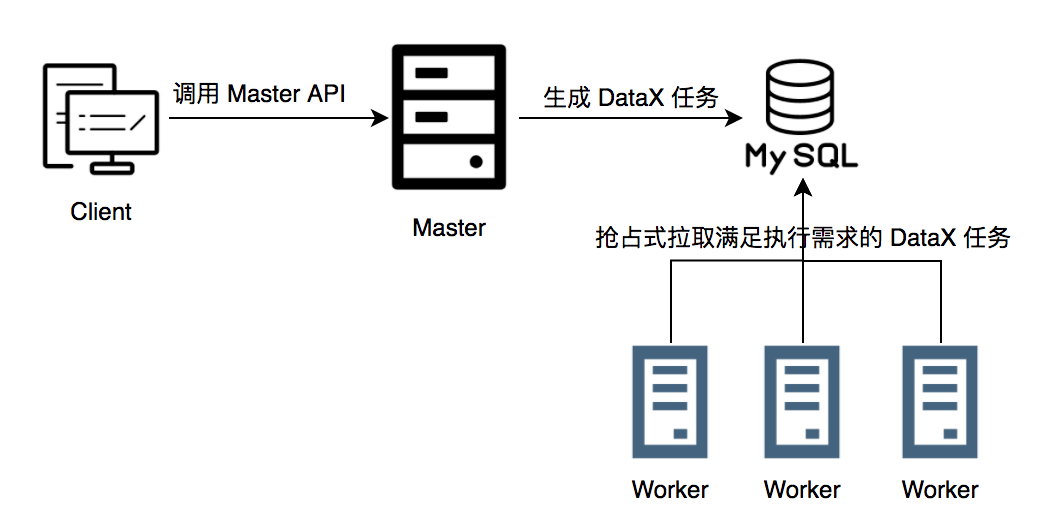
Worker 处理的过程如下:
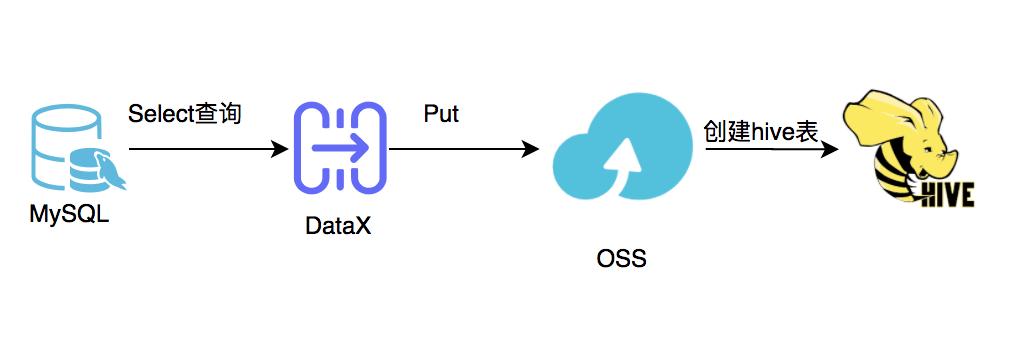
对于近实时需求,我们是直接开一个从库,配置 presto connector 去连接从库,来实现业务 BD 中的数据和 hive 中的数据做近实时的联合查询需求。
这种架构方案的优点是简单,易于实现。但是随着数据量也来越多,缺点也就逐渐暴露出来了:
性能瓶颈: 随着业务的增长,这种通过 SELECT 的方式接入数据的性能会越来越差,受 DB 性能瓶颈影响,无法通过增加 Worker 节点的方式来缓解。
规模大的表只能通过从库来拉取,造成数据接入的成本越来越高。
无法业务满足近实时的查询需求,近实时查询只能通过从库的方式查询,进一步加大了接入的成本。
为了解决这些问题,我们将目光聚焦到了 CDC实时接入的方案上。
技术方案选型
对于 CDC实时接入的方案,目前业内主要有以下几种: CDC + Merge 方案、CDC + Hudi、CDC + Delta Lake 及 CDC + Iceberg 等几种方案。其中,CDC + Merge 方案是在是在数据湖方案出现之前的做法,这种方案能节省DB从库的成本,但是无法满足业务近实时查询的需求等功能,所以最开始就 pass 掉了,而 Iceberg 在我们选型之初,还不够成熟,业界也没有可参考的案列,所以也被 pass 掉了,最后我们是在 CDC + Hudi 和 CDC + Delta Lake 之间选择。
在选型时,Hudi 和 Delta Lake 两者的功能上都是大同小异的,所以我们主要是从这几方案来考虑的: 稳定性、小文件合并、是否支持SQL、云厂商支持程度、语言支持程度等几个方面来考虑。
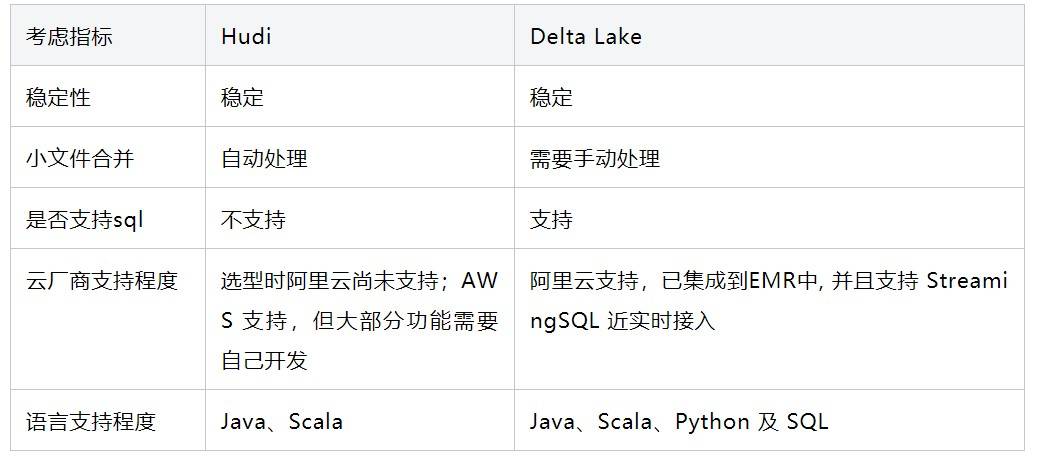
基于以上指标,加上我们整个数据平台都是基于阿里云 EMR 搭建的,选择 Delta Lake 的话,会省掉大量的适配开发工作,所以我们最终选择了 CDC + Delta Lake 的方案。
整体架构
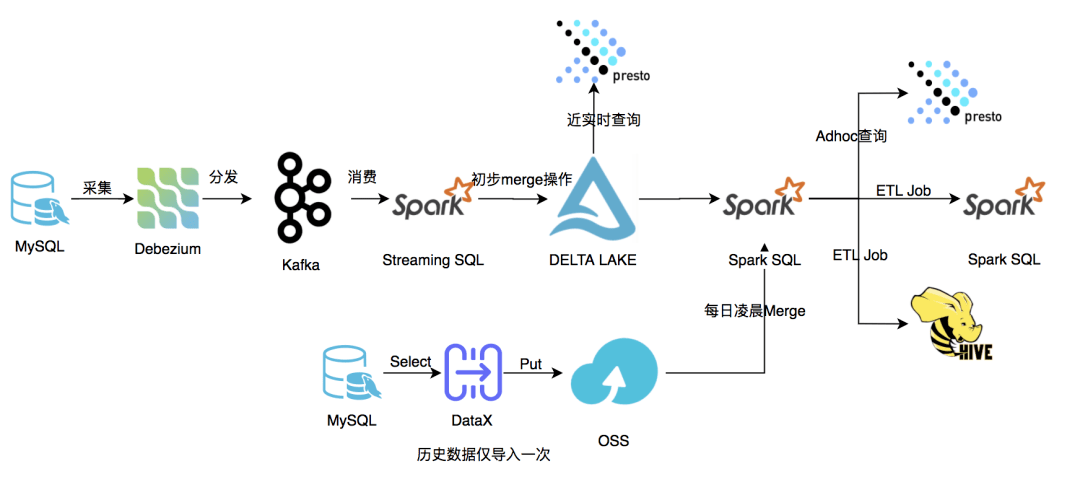
总体架构图
整体的架构如上图所示。我们接入的数据会分为两部分,存量历史数据和新数据,存量历史数据使用 DataX 从 MySQL 中导出,存入 OSS 中,新数据使用 Binlog 采集存入 Delta Lake 表中。每日凌晨跑 ETL 任务前,先对历史数据和新数据做 Merge 操作,ETL 任务使用 Merge 之后的数据。
Delta Lake 数据接入
在 Binlog 实时采集方面,我们采用了开源的 Debezium ,负责从 MySQL 实时拉取 Binlog 并完成适当解析,每张表对应一个 Topic ,分库分表合并为一个 Topic 分发到 Kafka 上供下游消费。Binlog 数据接入到 Kafka 之后,我们需要创建 Kafka Source 表指向对应的 Kafka Topic 中, 表的格式为:
CREATE TABLE kafka_{db_name}_{table_name} (key BINARY, value BINARY, topic STRING, partition INT, offset BIGINT, timestamp TIMESTAMP, timestampType INT)
USING kafka
OPTIONS (
kafka.sasl.mechanism ‘PLAIN’,
subscribe ‘cdc-{db_name}-{table_name}’,
serialization.format ‘1’,
kafka.sasl.jaas.config ‘*****(redacted)’,
kafka.bootstrap.servers ‘{bootstrap-servers}’,
kafka.security.protocol ‘SASL_PLAINTEXT’
我们主要用到的字段是 value 和 offset ,其中 value 的格式如下:
{
“payload”: {
“before”: {
db记录变更前的schema及内容,op=c时,为null
},
“after”: {
db记录变更后的schema及内容,op=d时,为null
},
“source”: {
ebezium配置信息
},
“op”: “c”,
“ts_ms”:
}
}
同时创建 Delta Lake 表,Location 指向 HDFS 或者 OSS ,表结构为:
CREATE TABLE IF NOT EXISTS delta.delta_{dbname}{table_name}(
{row_key_info},
ts_ms bigint,
json_record string,
operation_type string,
offset bigint
USING delta
LOCATION ‘——/delta/{db_name}.db/{table_name}’
其中 row_key_info 为 Delta Lake 表的唯一索引字段,对于单库单表而言,row_key_info 为 mysql 表的 primary key 字段 eg: id long,对于分库分表及分实例分库分表而言,row_key_info 为分库分表的字段和单表里primary key 字段组成,eg: 以 user_id 为分表字段,每张表里以 id 为 primary key , 那么对应的 row_key_info 为 id long, user_id long。
StreamingSQL 处理 Kafka 中的数据,我们主要是提取 Kafka Source 表中的 offset、value 字段及 value 字段中的 CDC 信息如: op、ts_ms 及 payload 的 after 和 before 字段。StreamingSQL 中,我们采用 5min 一个 mini batch,主要是考虑到 mini batch 太小会产生很多小文件,处理速度会越来越慢,也会影响读的性能,太大了又没法满足近实时查询的要求。而 Delta Lake 表,我们不将 after 或者 before 字段解析出来,主要是考虑到我们业务表 的 schema 经常变更,业务表 schema 一变更就要去修复一遍数据,成本比较大。在 StreamingSQL 处理过程中,对于 op=’c’ 的数据我们会直接 insert 操作,json_record 取 after 字段。对于 op=’u’ 或者 op=’d’ 的数据,如果 Delta Lake 表中不存在,那么执行 insert 操作, 如果存在,那么执行 update 操作;json_record 的赋值值,op=’d’,json_record 取 before 字段,op=’u’,jsonrecord 取 after 字段。保留 op=’d’ 的字段,主要是考虑到删除的数据可能在存量历史表中,如果直接删除的话,凌晨 merge 的数据中,存在存量历史表中的数据就不会被删除。
整个 StreamingSQL 的处理大致如下:
CREATE SCAN incremental{dbname}{tablename} on kafka{dbname}{table_name} USING STREAM
OPTIONS(
startingOffsets=’earliest’,
maxOffsetsPerTrigger=’1000000′,
failOnDataLoss=false
);
CREATE STREAM job
OPTIONS(
checkpointLocation=’——/delta/{db_name}.db/{table_name}checkpoint’,
triggerIntervalMs=’300000′
MERGE INTO delta.delta{dbname}{table_name} as target
USING (
SELECT * FROM (
SELECT ts_ms, offset, operation_type, {key_column_sql}, coalesce(after_record, before_record) as after_record, row_number() OVER (PARTITION BY {key_column_partition_sql} ORDER BY ts_ms DESC, offset DESC) as rank
FROM (
SELECT ts_ms, offset, operation_type, before_record, after_record, {key_column_include_sql}
FROM ( SELECT get_json_object(string(value), ‘$.payload.op’) as operation_type, get_json_object(string(value), ‘$.payload.before’) as before_record,
get_json_object(string(value), ‘$.payload.after’) as after_record, get_json_object(string(value), ‘$.payload.ts_ms’) as tsms,
offset
FROM incremental{dbname}{table_name}
) binlog
) binlog_wo_init ) binlog_rank where rank = 1) as source
ON {key_column_condition_sql}
WHEN MATCHED AND (source.operation_type = ‘u’ or source.operation_type=’d’) THEN
UPDATE SET {set_key_column_sql}, ts_ms=source.ts_ms, json_record=source.after_record, operation_type=source.operation_type, offset=source.offset
WHEN NOT MATCHED AND (source.operation_type=’c’ or source.operation_type=’u’ or source.operation_type=’d’) THEN
INSERT ({inser_key_column_sql}, ts_ms, json_record, operation_type, offset) values ({insert_key_column_value_sql}, source.ts_ms, source.after_record, source.operation_type, source.offset);
执行完 StreamingSQL 之后,就会生成如下格式的数据:
其中 part-xxxx.snappy.parquet 保存的是 DeltaLake 表的数据文件,而 _deltalog 目录下保存的是 DeltaLake 表的元数据,包括如下:
其中 xxxxxxxx 表示的是版本信息,xxxxxxxx.json 文件里保存的是有效的 parquet 文件信息,其中 add 类型的为有效的 parquet 文件, remove 为无效的 parquet 文件。
Delta Lake 是支持 Time travel 的,但是我们 CDC 数据接入的话,用不到数据回滚策略,如果多版本的数据一直保留会给我们的存储带来一定的影响,所以我们要定期删除过期版本的数据,目前是仅保留2个小时内的版本数据。同时,Delta Lake 不支持自动合并小文件的功能,所以我们还需要定期合并小文件。目前我们的做法是,每小时通过 OPTIMIZE 和 VACCUM 来做一次合并小文件操作及清理过期数据文件操作:
optimize delta{dbname}{tablename};
set spark.databricks.delta.retentionDurationCheck.enabled = false;
VACUUM delta{dbname}{table_name} RETAIN 1 HOURS;
由于目前 Hive 和 Presto 无法直接读取 Spark SQL 创建的 Delta Lake 表,但是监控及近实时查询需求,需要查询 Delta Lake 表,所以我们还创建了用于 Hive 和 Presto 表查询的。
Delta Lake 数据与存量数据 Merge
由于 Delta Lake 的数据我们仅接入新数据,对于存量历史数据我们是通过DataX 一次性导入的,加上 Delta Lake 表 Hive 无法直接查询,所以每日凌晨我们需要对这两部分数据做一次 merge 操作,写入到新的表中便于 Spark SQL 和 Hive 统一使用。这一模块的架构大致如下:
图片
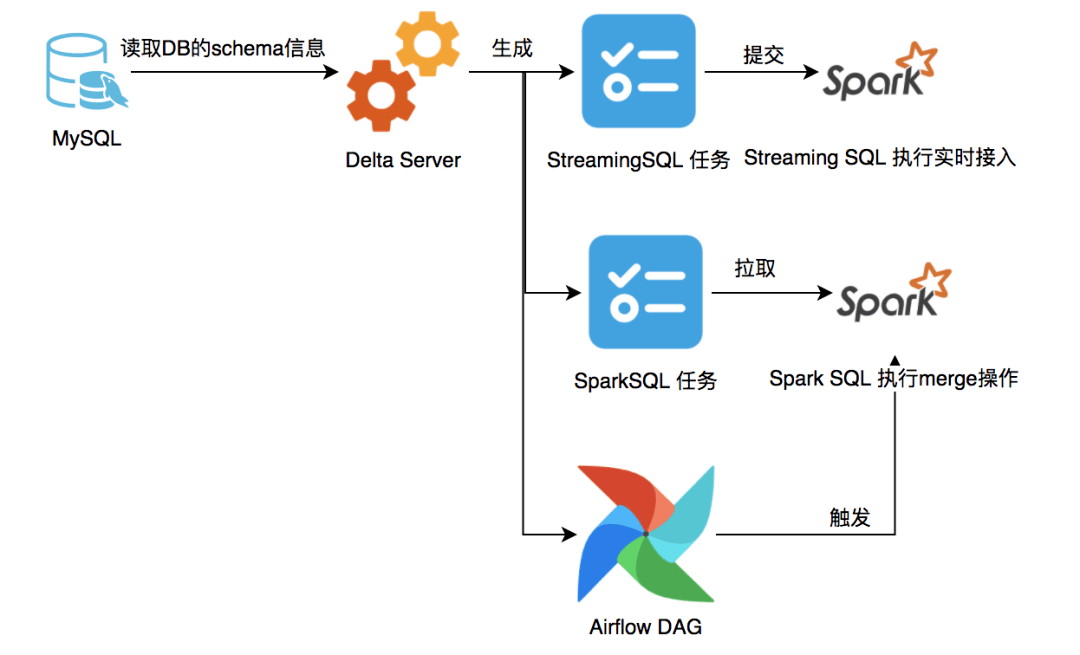
每日凌晨0点前,调用 DeltaService API ,根据 Delta Lake 任务的配置自动生成 merge任务 的 task 信息、spark-sql 脚本及 对应的 Airflow DAG 文件。
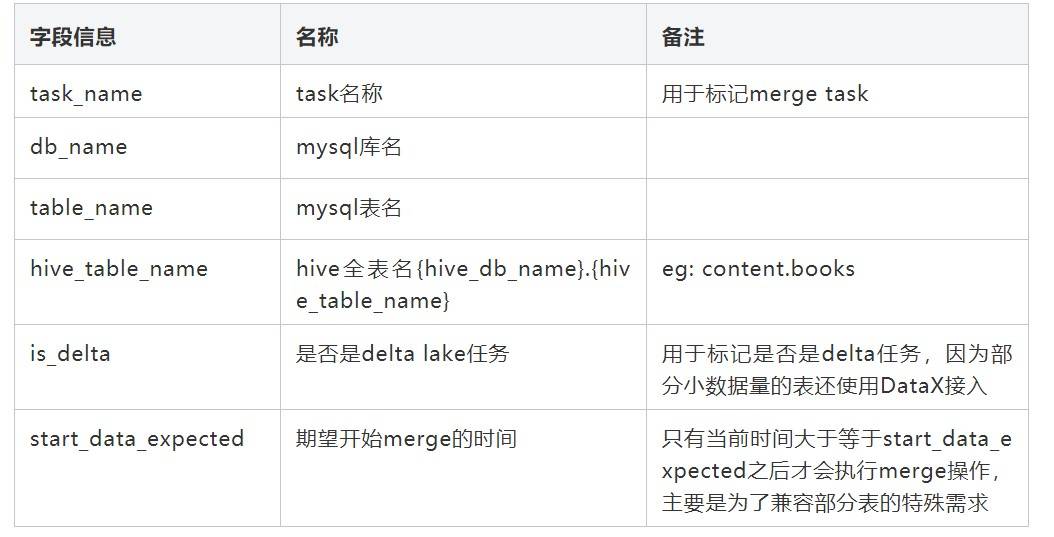
merge 任务的 task 信息主要包括如下信息:
自动生成 Merge 脚本,主要是从 Delta Lake 任务的配置中获取 mysql 表的schema 信息,删掉历史的 Hive 表,再根据 schema 信息重新创建 Hive 外部表,再根据新的 schema 从Delta Lake表的 json_record 字段和历史存量数据表中获取对应的字段值做 union all 操作,缺失值采用mysql 的默认值, union 之后,再根据 row_key 进行分组,按 ts_ms 排序取第一条,同时取出operation_type=’d’ 的数据。整体如下:
CREATE DATABASE IF NOT EXISTS {db_name} LOCATION ‘——/delta/{db_name}.db’;
DROP TABLE IF EXISTS {db_name}.{table_name};
CREATE TABLE IF NOT EXISTS {db_name}.{table_name}(
{table_column_infos}
STORED AS PARQUET
LOCATION ‘——/delta/{db_name}.db/{table_name}/data_date=${{data_date}}’;
INSERT OVERWRITE TABLE {db_name}.{table_name}
SELECT {table_columns}
FROM ( SELECT {table_columns}, _operation_type, row_number() OVER (PARTITION BY {row_keys} ORDER BY ts_ms DESC) as ranknum
FROM (
SELECT {delta_columns}, operation_type as _operation_type, tsms
FROM delta{dbname}{table_name}
UNION ALL
SELECT {hive_columns}, ‘c’ as _operation_type, 0 as ts_ms
FROM {db_name}.{table_name}_delta_history
) union_rank
) ranked_data
WHERE ranknum=1
AND _operation_type <> ‘d’
凌晨0点之后,Airflow 会根据 Airflow DAG 文件自动调度执行 merge 的Spark SQL 脚本,脚本执行成功后,更新 merge task 的状态为 succeed ,Airflow 的 ETL DAG 会根据merge task 的状态自动调度下游的 ETL 任务。
Delta Lake 数据监控对于 Delta Lake 数据的监控,我们主要是为了两个目的:监控数据是否延迟及监控数据是否丢失,主要是在 MySQL 与 Delta Lake 表之间及 CDC 接入过来的 Kafka Topic 与 Delta Lake 表之间。
CDC 接入过来的 Kafka Topic 和 Delta Lake 表之间的延迟监控:我们是每15分钟从 Kafka 的 Topic 中获取每个 Partition 的最大 offset 对应的 mysql 的 row_key 字段内容,放入监控的 MySQL 表 delta_kafka_monitor_info 中,再从 delta_kafka_monitor_info 中获取上一周期的 row_key 字段内容,到 Delta Lake 表中查询,如果查询不到,说明数据有延迟或者丢失,发出告警。
MySQL 与 Delta Lake 之间的监控:我们有两种,一种是探针方案,每15分钟,从 MySQL 中获取最大的 id,对于分库分表,只监控一张表的,存入 delta_mysql_monitor_info 中,再从 delta_mysql_monitor_info 中获取上一周期的最大 id,到 Delta Lake 表中查询,如果查询不到,说明数据有延迟或者丢失,发出告警。另一种是直接 count(id),这种方案又分为单库单表和分库分表两种,元数据保存在 mysql 表 id_based_mysql_delta_monitor_info 中,主要包含 min_id、max_id、mysql_count 三个字段,对于单库单表,也是每隔5分钟,从 Delta Lake 表中获取 min_id 和 max_id 之间的 count 值,跟 mysql_count 对比,如果小于 mysql_count 值说明有数据丢失或者延迟,发出告警。再从 mysql 中获取 max(id) 和 max_id 与 max(id) 之间的 count 值,更新到 id_based_mysql_delta_monitor_info 表中。对于分库分表的情况,根据分库分表规则,生成每一张表对应的 id_based_mysql_delta_monitor_info 信息,每半小时执行一遍监控,规则同单库单表。
遇到的挑战
业务表 schema 变更频繁,Delta Lake 表如果直接解析 CDC 的字段信息的话,如果不能及时发现并修复数据的话,后期修复数据的成本会较大,目前我们是不解析字段,等到凌晨 merge 的时候再解析。
随着数据量越来越大,StreamingSQL 任务的性能会越来越差。我们目前是 StreamingSQL 处理延迟,出现大量延迟告警后,将 Delta Lake 存量数据替换成昨日 merge 后的数据,再删掉 Delta Lake 表,删除 checkpoint 数据,从头开始消费 KafkaSource 表的数据。降低 Delta Lake 表数据,从而缓解StreamingSQL 的压力。
Hive 和 Presto 不能直接查询 Spark SQL 创建的 Delta Lake 表,目前我们是创建支持 Hive 和 Presto 查询的外部表来供 Hive 和 Presto 使用,但是这些表又无法通过 Spark SQL 查询。所以上层 ETL 应用无法在不更改代码的情况下,在 Hive 和 Spark SQL 及Presto 引擎之间自由切换。
带来的收益
节省了 DB 从库的成本,采用 CDC + Delta Lake 之后,我们的成本节省了近80%。
凌晨 DB 数据接入的时间成本大大降低,能够确保所有非特殊要求的 DB 数据接入都能在1个小时内跑完。
后续规划
StreamingSQL 任务随着 Delta Lake 表数据量越来越大,性能越来越差问题跟进。
推动能否解决 Spark SQL 创建的 Delta Lake 表,无法直接使用 Hive 和 Presto 查询的问题。
作者:张宽天