原标题:苹果 M1 芯片预示着 RISC-V 完全替代 ARM?
来源 | CSDN(ID:CSDNnews)
作者 | Erik Engheim 已获作者翻译授权
译者 | 弯月 责编 | 张文
编者按:M1 芯片性能强劲的背后主要源自两个因素:第一,M1芯片使用了大量的解码器和乱序执行;第二,就是异构计算。本文着重讲解第二点。
在大家了解了 M1 芯片表现之后,你肯定想一探究竟其底层核心是什么,本文将从异构计算开始讲起。
苹果非常热衷于添加多个专用硬件单元的策略,在本文中,我将其称为协处理器(coprocessor):
图形处理单元(GPU),用于图形处理以及其他需要并行处理大量数据的任务(即同时对多个元素执行相同的操作)。
神经引擎,机器学习的专用硬件。
图像处理的数字信号处理硬件。
硬件中的视频编码。
图形处理单元(GPU),用于图形处理以及其他需要并行处理大量数据的任务(即同时对多个元素执行相同的操作)。
神经引擎,机器学习的专用硬件。
图像处理的数字信号处理硬件。
硬件中的视频编码。
苹果没有在解决方案中添加更多的通用处理器,而是添加了更多的协处理器。你可以称之为加速器。这种趋势并不是新出现的,我从 1985 年开始使用的老式 Amiga 1000 就使用协处理器来加快音频和图形处理的速度。现代 GPU 本质上就是协处理器。Google 的 Tensor 处理单元也是一种用于机器学习的协处理器。

图:Google TPU是专用集成电路(ASIC),我们称之为协处理器。
01
什么是协处理器?
与 CPU 不同,协处理器不能单独存在。只使用协处理器无法造出计算机。协处理器作为专用处理器,可以很好地完成某些特定的任务。最早的协处理器当属英特尔 8087 浮点单元(FPU)。英特尔的 8086 微处理器可以执行整数运算,但不能执行浮点运算。这两者的区别是什么?

图:英特尔 8087,最早的执行浮点计算的协处理器之一。
整数都是这样的数字:43、-5、92、4。对于计算机来说,处理这些数字比较容易。你可能只需要将一些简单的芯片组合在一起,就能处理整数加法。
然而,小数处理就没那么简单了。
假设你需要执行小数的加法或乘法:4.25、84.7 或 3.1415。这些是浮点数。如果小数点后面的位数是固定的,则我们称之为 定点数。金钱通常都保留两位小数,因此都是通过定点数处理的。
然而,你可以使用整数来模拟浮点运算,只不过速度会比较慢。与之类似,早期的微处理器只能处理整数的加法,不能处理乘法。但是,它们仍然可以执行乘法,因为你只需要通过多次的加法来模拟乘法。例如 3×4 = 4 + 4 + 4。
理解下面的示例代码并不重要,但是可以帮助你理解 CPU 如何通过加、减和分支(代码跳转)来执行乘法。
loadi r3, 0 ; Load 0 into register r3multiply: add r3, r1 ; r3 ← r3 + r1dec r2 ; r2 ← r2 – 1bgt r2, multiply ; goto multiply ifr2 > 0
简而言之,你可以通过重复简单的运算来实现更复杂的数学运算。
所有协处理器的工作方式都与之类似。CPU 总有方法完成协处理器的任务。但是,通常这都需要重复多个更简单的操作。我们之所以使用 GPU,是因为对数百万个多边形或像素重复相同的计算,对于 CPU 来说确实很耗时。
02
如何与协处理器来回传输数据
我们来看一看下面的示意图,以更好地了解协处理器如何与微处理器(CPU)或通用处理器的协同工作。
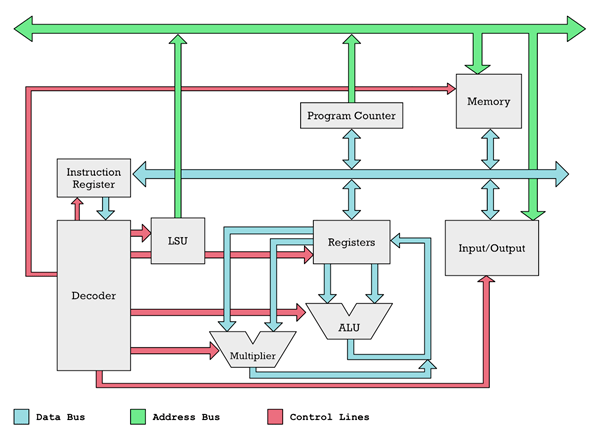
图:微处理器的工作原理概述。
数字沿彩色线移动。输入/输出可以是协处理器、鼠标、键盘以及其他设备。
我们可以将绿色和浅蓝色的公共总线视为管道。数字通过这些管道推送到 CPU 的不同功能单元(图中为灰色盒子)。这些盒子的输入和输出连接到了管道。
你可以认为每个盒子的输入和输出都带有阀门。红色控制线可用于打开和关闭这些阀门。因此,负责红线的解码器(Decoder)可以打开两个灰色盒子上的阀门,让数字在它们之间流动。
图:你可以将数据总线视为管道,而红色控制线则负责打开和关闭阀门。
但是,在电子设备中,这是通过我们所谓的多路复用器完成的,而不是实际的阀门。
下面,我们来介绍一下如何从内存中获取数据。
如果想执行数字运算,则首先需要将数字放入寄存器中。解码器使用控制线打开灰色盒子“内存”和“寄存器”之间的阀门。具体操作为:
解码器打开负载存储单元(LSU)上的阀门,内存地址从绿色地址总线上流出。
打开内存盒上的阀门,这样它就可以接收地址了,而地址由绿色管道(地址总线)负责传送。所有其他阀门都关闭,这样输入/输出就无法接收地址。
选中地址指定的内存单元。然后解码器会打开通往数据总线的阀门,这样选定内存单元的内容就会流出到蓝色数据总线上。
内存单元的数据可以流到任何地方,但是解码器仅打开了寄存器的输入阀门。
鼠标、键盘、显示器、GPU、FPU、神经引擎和其他协处理器都是“输入/输出”盒子。访问方式与访问内存一样。硬盘驱动器、鼠标、键盘、网卡、GPU、DMA(直接内存访问)和协处理器都被映射到自己的内存地址。
举个例子,如果处理器尝试从内存地址 84 读取数据:鼠标的 x 坐标,而 85 代表鼠标的 y 坐标。
因此,为了获取鼠标坐标,你可以通过汇编代码中执行以下操作:
load r1, 84 ; get x-coordinateloar r2, 85 ; get y-coordinate
对于 DMA 控制器,可能地址 110、111 和 113 有特殊的含义。下面这些伪汇编代码可以使用这些地址与 DMA 控制器进行交互:
loadi r1, 1024 ; set register r to source addressloadi r2, 50 ; bytes to copyloadi r3, 2048 ; destination address
store r1, 110 ; tell DMA controller start addressstore r2, 111 ; tell DMA to copy 50 bytesstore r3, 113 ; tell DMA where to copy 50 bytes to
一切都以这种方式工作。你只需读写特殊的内存地址。
当然,一般软件开发人员不需要知道这些,这些工作都是由设备驱动程序完成的。你使用的程序无法真正看到这些不可见的虚拟内存地址。但是,驱动程序会将这些地址映射到其虚拟内存地址。

我不打算过多地讨论虚拟内存。
本质上,我们拿到的是真实的地址。绿色总线上的地址将从虚拟地址转换为实际物理地址。当我在 DOS 中编写 C/C++的程序时,就不会遇到这种情况。我可以将 C 指针直接指向视频的内存地址,然后直接修改图片。
char *video_buffer = 0xB8000; // set pointer to CGA video buffervideo_buffer[3] = 42; // change color of 4th pixel
协处理器的工作方式与此相同。神经引擎、GPU、安全协处理器(Secure Enclave)都拥有可以与之通信的地址。你需要了解这些,同时也需要了解 DMA 控制器可以异步工作。
这意味着 CPU 可以为神经引擎或 GPU 安排一整套指令,并将它们写入内存的缓冲区。然后,通过与 IO 地址的对话,将这些指令的位置通知给神经引擎或 GPU 协处理器。
你肯定不希望 CPU 处于空闲状态,等待协处理器仔细检查所有指令和数据。你也不想让 DMA 遇到这种情况。这就是为什么一般我们都需要使用某种中断的原因。
03
中断如何工作?
你插入到 PC 的各种卡,无论是显卡还是网卡,都将分配一些中断线。就像一条直接插入 CPU 的线。这条线被激活后,CPU 就会放下手头所有的工作来处理中断。更具体地说,CPU 会将自己的当前位置及其寄存器的值存储在内存中,以方便回头可以随时返回之前的工作。接下来,CPU 会查看中断表需要做什么。这个表存储了中断被触发时需要运行的程序的地址。
作为程序员,你很少看见这些东西。对你来说,你看到的更多的是某些事件注册的回调函数。这些底端的问题一般都是由驱动程序处理的。
我之所以唠叨了这么多,就是希望帮助你了解使用协处理器时究竟发生了什么。否则,你就搞不清楚协处理器实际上需要进行哪些通信。
我们可以通过中断并行处理很多任务。 当 CPU 被计算机鼠标中断时,应用程序可以通过网卡获取图像。鼠标移动时,我们需要新的坐标。CPU 可以读取这些并将其发送到 GPU,然后在新位置上显示鼠标光标。当 GPU 绘制鼠标光标时,CPU 可以趁这段时间处理从网络检索到的图像。
就像使用这些中断一样,我们也可以将复杂的机器学习任务发送给 M1 神经引擎,要求它通过网络摄像头设别人脸。同时,计算机的其余部分依然在响应,因为在神经引擎处理图像数据期间,CPU 正在处理其他工作。

图:SiFive 的基于 RISC-V 的主板,能够运行 Linux
04
RISC-V 的崛起
早在 2010 年,加州大学伯克利分校的并行计算实验室就大量使用了协处理器。他们预见了摩尔定律的终结,意味着我们无法再从通用 CPU 核心压榨出更多性能。 我们需要专用的硬件:协处理器。
我们来反思一下为什么。我们知道增加时钟频率并不容易。我们一直徘徊在 3–5 GHz,无法突破。进一步增加时钟频率,那么功耗和散热就会出问题。
但是,我们可以添加更多的晶体管。只是我们无法加快晶体管的工作速度。因此,我们需要并行处理很多工作。一种方法是添加大量通用核心。正如我之前讨论的那样,我们可以添加很多解码器并执行乱序执行。
05
晶体管预算:CPU 核心还是协处理器?
我们可以无止境地增加 CPU 核心,最后就会得到 Ampere Altra Max ARM 处理器之类 128 个通用核心的处理器。
但这真的是芯片的最佳用法吗?对于云服务器而言,这个方法没问题。我们可以通过 128 个核心处理各种客户端请求。但是,台式机系统可能甚至无法有效地利用普通台式机工作负载上的 8 个以上的核心。因此,即便你拥有 32 个核心,其实大部分也都被浪费了。
既然不能增加更多 CPU 核心,那么,我们可以添加更多的协处理器吗?
我们来算一笔账:你有一个晶体管预算。早先,也许你有 2 万个晶体管的预算,你发现可以利用这些晶体管制造出具有 1.5 万晶体管的 CPU。这与 80 年代初的真实情况很相似。现在,这个 CPU 可以执行 100 个不同的任务。假设为其中一项任务制作专用的协处理器,将花费 1000 晶体管。如果你为每一个任务创建一个协处理器,那么就需要 10 万个晶体管。这会超过你的预算。
06
过多的晶体管改变了策略
因此,早期的设计需要专注于通用计算。但是今天,我们的芯片中可以塞入太多的晶体管,但却不知道该用这些晶体管做什么。
因此,协处理器的设计就成为了一个大问题。
制作各种新型协处理器的相关研究很多。然而,这些研究经常会造出非常笨拙的加速器,我们需要加以制止。与 CPU 不同,它们无法读取自己需要执行的指令步骤。一般,它们都不知道如何访问内存或组织任何事情。
因此,常见解决方案是 将一个简单的 CPU 作为一种控制器。因此,整个协处理器都是由一个简单的 CPU 控制的专用加速器电路,CPU 负责配置加速器完成工作。通常这都是高度专业化的工作。例如,神经引擎或张量处理单元等处理的是非常大的寄存器,可以容纳矩阵。
07
通过量身定制的 RISC-V 控制加速器
这正是 RISC-V 的设计初衷。它仅有约 40–50 条指令的最低限度指令集,可以完成所有常见的 CPU 工作。听起来可能很多,但别忘了,x86 CPU 包含 1500 多个指令。
RISC-V 不需要一套大型的固定指令集,它是围绕扩展的概念设计的。每个协处理器都是不同的。因此,它将包含一个 RISC-V 处理器来管理核心指令集的实现,以及根据协处理器需要处理的任务而定制的扩展指令集。
苹果 M1 芯片就在推动整个行业朝着协处理器主导的未来发展。而在协处理器的制造中,RISC-V 将成为重要的一环。
为什么?制作协处理器的人不能发明自己的指令集吗?不过,我认为苹果已经做到了,或者可能他们使用了 ARM,我不清楚。如果有人知道,请在下方留言。
08
坚持在协处理器中采用 RISC-V 有什么好处?
制造芯片已成为一件复杂而耗费巨大的工作。我们需要建立验证芯片的工具,运行测试程序,运行诊断程序,以及其他很多的事情都需要付出努力。
这是当前使用 ARM 的优势之一。他们拥有庞大的工具生态系统,可以帮助你验证设计,并测试芯片。因此,寻求定制的专有指令集并不是一个好主意。但是,使用 RISC-V 可以为多家公司提供标准工具。就好像突然出现了生态系统,然后由多家公司共同负担。
那么,为什么不能使用已有的 ARM 呢?ARM 主要面向通用 CPU。它拥有大型的固定指令集。在客户和 RISC-V 竞争的压力下,ARM 放低了姿态,并于 2019 年开放了扩展指令集。
但是,问题仍然存在,因为当初它的设计初衷不在于此。整个 ARM 工具链会假定你已经实现了整个大型 ARM 指令集。这对于 Mac 或 iPhone 的主 CPU 来说没什么问题。但是对于协处理器,你不想要或不需要这么大的指令集。你只需要一个围绕基础固定扩展指令集而构建的工具生态系统。
为什么这样会有好处?Nvidia 使用 RISC-V 的方法为我们提供了一些思路。在大型 GPU 上,他们需要某种通用 CPU 作为控制器。但是,为此目的保留的晶体管数量以及允许为此产生的热量都是有限的,并将产生的热量降到最低。请记住,有很多晶体管在争夺芯片这片狭小的空间。
由于 RISC-V 的指令集又小又简单,因此它击败了包括 ARM 在内的所有竞争对手。Nvidia 发现,选择 RISC-V 可以制造出比其他任何产品都小的芯片,而且还可以将功耗降至最低。因此,你可以通过这种扩展机制,只添加对完成必须的工作至关重要的指令。而对于 GPU 的控制器,除了加密协处理器上的控制器以外,还需要其他扩展。
09
ARM 将成为新一代 x86
具有讽刺意味的是,我们可能会看到未来 Mac 和 PC 都由 ARM 处理器来驱动。但是,周边所有的定制硬件,所有协处理器都将由 RISC-V 主导。随着协处理器变得越来越流行,运行 RISC-V 的单片系统(SoC)的数量可能会超过 ARM。
10
ARM 指挥的 RISC-V 协处理器大军
通用 ARM 处理器将成为 RISC-V 驱动的协处理器的中心,从图形、加密、视频编码、机器学习、信号处理到处理网络程序包,所有任务都可以得到加速。
加州大学伯克利分校的教授 David Patterson 和他的团队预见了这一未来,而且这也是经过精心设计后的 RISC-V 完全可以适应这个新世界的原因。
我们看到 RISC-V 在各种专门的硬件和微控制器中都得到了广泛的应用和关注,我认为如今 ARM 主导的许多领域都将归入 RISC-V 旗下。

图:树莓派 4 微控制器,当前使用的是 ARM 处理器。
试想一下树莓派等设备,如今运行的都是 ARM,但是将来树莓派的 RISC-V 版本可能会提供能够满足各种需求的变体。有些是机器学习微控制器,有些面向图像处理,而有些则用于加密。
简单来说,你可以挑选自己的带有微调功能的微控制器。当然,你可以在其上运行 Linux,并执行所有相同的任务,只是性能会有所不同。带有特殊机器学习指令的 RISC-V 微控制器训练神经网络的速度将远远超过带有视频编码指令的 RISC-V 微控制器。
英伟达的 Jetson Nano 已经走上这条冒险之路,如下图所示。这款微控制器只有树莓派那么大,拥有机器学习的专用硬件,因此,你可以利用它执行对象检测、语音识别以及其他机器学习任务。

图:英伟达的 Jetson Nano 开发者套件
11
将 RISC-V 作为主 CPU?
许多人可能想问:为什么不用 RISC-V 完全替代 ARM?
尽管有些人认为这根本无法实现,因为 RISC-V 拥有一套“精巧又简单”的指令集,无法提供 ARM 和 x86 的高性能。实际上,你可以将 RISC-V 作为主处理器。性能并不是问题。就像使用 ARM 一样,我们只需要有人来制作高性能 RISC-V 芯片。
实际上,已经有人制作出了这样的芯片:新的 RISC-V CPU 宣称性能已创纪录。
人们常常有一个误解:复杂的指令可以提供更高的性能。RISC 工作站在 90 年代就证明了这是错误的想法,它们在性能基准测试中彻底击败了 x86 计算机。实际上,RISC-V 有很多巧妙的方法来提高性能。简而言之,你完全可以将 RISC-V 处理器作为主 CPU,但这也是一个时机的问题。MacOS 和 Windows 都采用了 ARM。至少在短期内,微软或苹果是否会再次投资硬件以支持 RISC-V 似乎很值得怀疑。
12
总结
有人声称 RISC-V CPU 在功耗和性能方面已经超过了 ARM。人们纷纷在讨论,RISC-V 是否确实有可能成为计算机的主 CPU。
我必须承认,我不清楚为什么 RISC-V 会超过 ARM。而且他们自己也承认, RISC-V 是一个非常保守的设计,其中并没有使用太多新的指令。但是,采用最小指令集确实有优势。我们可以实现非常小且非常简单的 RISC-V CPU,同时功耗会降低,而时钟频率可以提升。
因此,关于 RISC-V 和 ARM 的最终结论还为时尚早。
原文链接:https://erik-engheim.medium.com/apple-m1-foreshadows-risc-v-dd63a62b2562
原文标题:Apple M1 foreshadows Rise of RISC-V
作者:Erik Engheim,现居挪威,热衷于 UX、Julia 编程、科学与写作。