原标题:输入文字就能画出图片!人工智能再进一步

旧金山人工智能研究公司OpenAI已经开发了一种新系统,能根据短文本来生成图像。OpenAI表示,这个新系统名为DALL-E,名称来源于艺术家萨尔瓦多·达利(Salvador Dali)和皮克斯动画瓦力(WALL-E)的结合。
新的AI有多厉害呢?只需要输入文字,它就能根据描述,生成图片。比如,在DALL·E模型中输入“穿芭蕾舞短裙、正在遛狗的萝卜宝宝”,它就可以生成这样一张图片:

输入“鳄梨形状的扶手椅”,就是这样:

甚至输入“含OpenAI字样的店铺”,它也能生成多种设计图

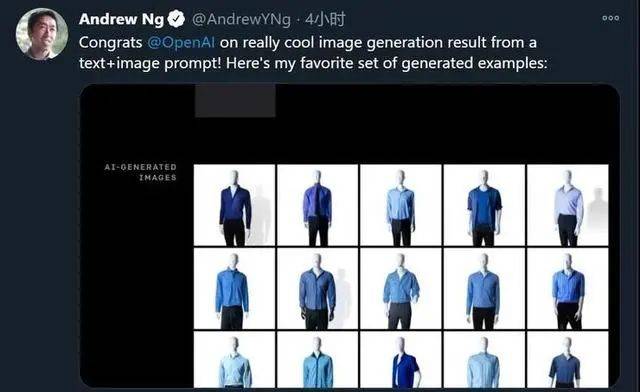
人工智能“大神”吴恩达也第一时间转推点赞,还顺带挑选了一张满意的蓝色衬衫 + 黑色长裤的AI 生成图。
在系统中,可以随时根据需求进行调整:

比如:乌龟身子长颈鹿脖子的“物种”只要告诉它,就能呈现相关图像:

同时控制多个对象、它们的属性以及它们的空间关系,对模型提出了新的挑战。例如,考虑 “一只刺猬戴着红色的帽子、黄色的手套、蓝色的衬衫和绿色的裤子 “这句话,为了正确解释这个句子,DALL-E不仅要正确地将每件衣服与动物结合起来,而且要形成(帽子,红色)、(手套,黄色)、(衬衫,蓝色)和(裤子,绿色)的关联,不能将它们混为一谈。
研究人员测试了DALL-E在相对定位、堆叠对象和控制多个属性方面的能力。例如:一个Emoji的小企鹅,带着蓝帽子,红手套,穿着黄裤子。

虽然DALL-E确实在一定程度上提供了对少量物体属性和位置的可控性,但成功率可能取决于文字的措辞。当引入更多的对象时,DALL-E容易混淆对象及其颜色之间的关联,成功率会急剧下降。研究人员还注意到,在这些情况下,DALL-E对于文字的重新措辞是很脆弱的:替代的、语义等同的标题往往也不会产生正确的解释。
今天AI学会了画图,谁知道下一步会的是什么呢?
